
page4(update:2017/10/23)[例題4a|例題4b|例題4c|例題4d]
java言語では変数のデータ型は基本データ型か参照データ型です。
オブジェクトを参照する変数は作れますが格納する変数は作れません。(4.2参照データ型 を見てください)
1)基本データ型 文字、整数、実数などのデータを直接格納する型。
同じプログラムが何処でも動くように表現方法が一意に決められています。
2)参照データ型 インスタンス (オブジェクト)を参照するための値である参照を格納する型。
C言語のポインター型に相当する型です。
インスタンスはnew演算子を使って動的メモリー確保を行い、その場所にデータを格納します。このとき、new演算子が戻す値はインスタンスを参照するための値で参照(reference)と呼ばれます。この参照を記憶するデータ型が参照データ型です。
インスタンスの変数(フィールド)の読み書きや、関数(メソッド)の呼び出しは、すべて参照データ型変数からの間接参照で行います。
※Java言語のクラスはクラスのメンバーを持ち、オブジェクトとして振る舞えますが、クラスを参照する変数は作れません。クラスのメンバの操作はクラス名を使って行います。
※C言語のポインターでは変数のアドレスをアドレス演算子&で入手できるので、変数を参照する変数が作れました。しかし、javaでは変数の参照は入手できないので、C言語のような変数を参照する変数は作れません。
目次
[目次]
整数、浮動小数点数、真偽値、文字などのデータを表記するデータ型。Pascal,C/C++等のデータ型と同様だが、Javaの特徴は従来のC言語にみられた計算機のCPUやOSに依存してint型が16ビットや32ビットになったりはしないことである。これは、Javaがどの計算機でも同じプログラムがそのまま動くことを重視しているからで、それぞれのCPUの性能を極限まで引き出すことが期待されたC言語とは対照的です。
以下javaの基本データ型を示す。
| 型名 | bit長 | データの種類 | 値の範囲 |
| boolean | 1ビット | 真偽値 | false、true |
| char | 16ビット | 文字 (Unicode 2.0を使用) |
\u0000〜\uFFFF
U+FFFF よりも大きいコードポイントを持つ「補助文字」は 2個のcharで表現するのでchar型の値として格納できない。 |
|
|
|||
| byte | 8ビット | 符号付き整数 (2の補数を使用) |
-128〜127 |
| short | 16ビット | -32768〜32767 | |
| int | 32ビット | -2147483648〜2147483647 | |
| long | 64ビット | -9223372036854775808〜9223372036854775807 | |
| float | 32ビット | 浮動小数点数 (IEEE754準拠) |
±3.40282347E+38 〜 ±1.4E-45と 0, ±無限大Infinity、非数NaN |
| double | 64ビット | ±1.79769313486231570E+308 〜 ±4.9E-324と 0, ±無限大Infinity、非数NaN |
|
文字はUnicodeで表現され、整数のデータは2の補数表示で、実数はIEEE754に準じて表現される。
真偽をしめすデータ型booleanが在ります。if文等の真偽はboolean型のデータのみを評価します。
真偽を表すリテラルとしてtrueとfalseが予約語となっています。
public class TestBoolean
{
public static void main(String args[])
{
boolean t=true;
boolean f= !t;//f=false;と同じ結果になる
//
System.out.printf( "%-7s %-7s %-7s %n", "a & b", "b=true", "b=false");
System.out.printf( "%-7s %-7b %-7b %n", "a=true" , t & t , t & f);
System.out.printf( "%-7s %-7b %-7b %n", "a=false", f & t , f & f);
//printfはC言語の標準関数に類似した書式付書き出しメソッド
//%bはboolran型の書式指定子 オプションの-7は左詰めで7文字の指定
//%nは環境に応じた改行コードに変換される
System.out.println();
System.out.printf( "%-7s %-7s %-7s %n", "a | b", "b=true", "b=false");
System.out.printf( "%-7s %-7b %-7b %n", "a=true" , t | t , t | f);
System.out.printf( "%-7s %-7b %-7b %n", "a=false", f | t , f | f);
}
}
/* 実行結果
a & b b=true b=false
a=true true false
a=false false false
a | b b=true b=false
a=true true true
a=false true false
*/
javaの文字コードは国際化のためにユニコードUTF-16を採用し、文字のデータ型charは16ビットのデータ型と成っています。
ユニコードではACSIIコードの0x00〜0x7FはそのままUnicodeの\u0000〜\u007Fに対応付けする
日本語の文字も多くがそのままchar型変数に代入できます。
public class TestChar
{
public static void main(String args[])
{
char a='A';
char b='あ';/*C言語の場合、この代入は不可*/
System.out.printf("a=%c b=%c",a,b);
}
}
/* 実行結果
a=A b=あ
*/
※ASCIIコード中の半角バックスラッシュ( \ )とチルダ(〜)の場所に、JISコードでは半角の 円記号「\」とオーバースコア「 ̄」 が割り当てられている。Unicodeでは円記号は\u00A5にオーバースコアは\u203Eにと別の場所に対応付けされている。
※javaのライブラリーの中で日本語のJIS、SJIS、、EUC等のバイト列をUnicodeの文字列に変換する機能を提供している。
ユニコードUTF-16の範囲はU+0000 〜 U+10FFFFだが2バイトで格納できるのはU+FFFFまでである。これを超えるコードポイントを持つ 文字は「補助文字」と言う。補助文字はchar型には格納できないが、Stringや文字配列に格納する場合は「上位サロゲート」範囲 (\uD800-\uDBFF) からの最初の値と、「下位サロゲート」範囲 (\uDC00-\uDFFF) からの第 2 の値から構成されるchar 2個で1文字を表現する。 intに格納する場合は上位11ビットを0とし下位21ビットにコードを格納する。
byte型は8bit、8bitでは256通りのものを区別できる。これを下記の様に正負の値に割り当てる
public class TestByte
{
public static void main(String args[])
{
byte a=0;
for(int i=0; i<17;i++){
for(int k=0;k<16;k++){
System.out.printf("%4d ",a);
a++;
}
System.out.println();/*改行*/
}
}
}
/* 実行結果
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79
80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111
112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 <<この後、値がマイナスに跳ぶ
-128 -127 -126 -125 -124 -123 -122 -121 -120 -119 -118 -117 -116 -115 -114 -113
-112 -111 -110 -109 -108 -107 -106 -105 -104 -103 -102 -101 -100 -99 -98 -97
-96 -95 -94 -93 -92 -91 -90 -89 -88 -87 -86 -85 -84 -83 -82 -81
-80 -79 -78 -77 -76 -75 -74 -73 -72 -71 -70 -69 -68 -67 -66 -65
-64 -63 -62 -61 -60 -59 -58 -57 -56 -55 -54 -53 -52 -51 -50 -49
-48 -47 -46 -45 -44 -43 -42 -41 -40 -39 -38 -37 -36 -35 -34 -33
-32 -31 -30 -29 -28 -27 -26 -25 -24 -23 -22 -21 -20 -19 -18 -17
-16 -15 -14 -13 -12 -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
*/
符号:s bitが
0なら正s=1
1なら負s=-1を示す
指数部 eは8桁の2進数だがバイアス-127を加えて正負の領域を表現する
ただし全bitが0と1の場合には特別の意味を持つ
仮数部 23桁の2進数
指数部が 全て0 or 全て1 の場合を除いて
m=1.m1m2m3m...m23の正規化された2進小数値
指数部が 全て0 なら
m=0.m1m2m3m...m23の2進小数値
| 符号 1bit |
指数部 8bit |
仮数部 23bit |
値 |
| 0/1 | 全て0 | 0 | +0/-0 |
| 0/1 | 全て0 | 0以外 | ±2emin×0.m1m2.......m23 |
| 0/1 | -126<=e<127 | ±2e×1.m1m2......m23 | |
| 0/1 | 全て1 | 0 | ±Infinity:無限大 |
| 0/1 | 全て1 | 0以外 | NaN:非数 |
float型の有効数字は仮数部の23ビットから10進6-7桁であるが、指数部が全て0となる場合には有効桁はもっと少なくなる。最小値では10進1桁分もない。
double型の場合 符号1bit 指数部11bit(emin=-1022、emax=1023) 仮数部52bit 10進での有効数字15桁程度
実数doubleの内部表現は桁数が小数点以下52桁に制限される2進の小数点数です。2進数では循環小数になる値、10進数の0.1のような値は正確には表現できず丸め誤差を生じます。
public class TestDouble
{
public static void main(String args[])
{
double a=1.0;
a+=0.1;
a+=0.1;
if(a==1.2) System.out.printf("1.0+0.1+0.1は1.2です");
else System.out.printf("1.0+0.1+0.1は1.2ではありません");
}
}
/* 実行結果
1.0+0.1+0.1は1.2ではありません
*/
値の範囲を書き出すjavaプログラムを示す。実行してみて下さい
/*データ型の値の範囲を表示するアプリケーション*/
/*このプログラムのファイル名はType.java*/
public class Type{
/**main関数*/
static public void main(String arg[]){
//
//基本データ型のラッパークラスに定義された最大値、最小値の定数をプリント
//
System.out.println("-------------------------------------");
System.out.println("byte の最大値"+Byte.MAX_VALUE);
System.out.println("byte の最小値"+Byte.MIN_VALUE);
System.out.println("-------------------------------------");
System.out.println("short の最大値"+Short.MAX_VALUE);
System.out.println("short の最小値"+Short.MIN_VALUE);
System.out.println("-------------------------------------");
System.out.println("int の最大値"+Integer.MAX_VALUE);
System.out.println("int の最小値"+Integer.MIN_VALUE);
System.out.println("-------------------------------------");
System.out.println("long の最大値"+Long.MAX_VALUE);
System.out.println("long の最小値"+Long.MIN_VALUE);
System.out.println("-------------------------------------");
System.out.println("float の正の最大値"+Float.MAX_VALUE);
System.out.println("float の正の最小値"+Float.MIN_VALUE);
System.out.println("負の場合はこれに−が付くだけです");
System.out.println("float 1.0/0.0は"+(float)( 1.0/0.0));
System.out.println("float -1.0/0.0は"+(float)(-1.0/0.0));
System.out.println("float 0.0/0.0は"+(float)( 0.0/0.0));
System.out.println("-------------------------------------");
System.out.println("double の正の最大値"+Double.MAX_VALUE);
System.out.println("double の正の最小値"+Double.MIN_VALUE);
System.out.println("負の場合はこれに−が付くだけです");
System.out.println("double 1.0/0.0は"+(double)( 1.0/0.0));
System.out.println("double -1.0/0.0は"+(double)(-1.0/0.0));
System.out.println("double 0.0/0.0は"+(double)( 0.0/0.0));
System.out.println("-------------------------------------");
}
}
プログラム中に太字で示した部分は定数です。基本データ型と良く似た名前のクラスが用意されています。これらを基本データ型を包み込んだ(ラップした)クラスの意味でラッパークラス(wrapper class)と言います。この対応関係を下記に示します。
これらのクラスには文字列から基本データ型への変換など重要な関数がクラスのメソッドとして用意されています。使うときはクラス名.フィールドやクラス名.メソッド名の様にクラスとその中身を指定して使います。
これらのクラスのインスタンスは対応する基本データ型の値を持ったオブジェクトになります。クラスライブラリーとして用意されたデータ構造に基本データ型の値を格納するのに使えます。
|
基本データ型 |
ラッパークラス |
| boolean | Boolean |
| char | Character |
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
CharacterとIntegerだけは少し違いますが、後は先頭の文字が大文字に変えてあるだけで同じ名前です。
演算記号を以下に示します。論理演算の結果がbooleanになる以外はC言語とそれほど違わないと考えて良いでしょう。
| 優先順位 |
|
|
| 1 | ++ -- + - | ++と--は前置と後置の区別がある |
| 2 | * / % | 乗算 除算 剰余 |
| 3 |
+ - |
加算 減算 |
| 4 | << >> >>> | int型のビットシフト |
| 5 | < > <= >= instanceof | 比較とオブジェクト生成元の確認 |
| 6 | == != | 等号と不等号 |
| 7 | & | ビット単位と論理のAND |
| 8 | ^ | ビット単位と論理のXOR |
| 9 | | | ビット単位と論理のOR |
| 10 | && | 論理のAND(短絡的評価を行う) |
| 11 | || | 論理のOR(短絡的評価を行う) |
| 12 | ?: | 三項演算子 |
| 13 | = 演算付き代入(*= += ......) | 代入演算 |
※++は前置なら増やした後の値を、後置なら増やす前の値を返します。
a=10;System.out.println(++a);は11を書き出す
a=10;System.out.println(a++);は10を書き出す
※ <<と>>>はシフトで空いた部分を0で埋めますが、>>は符号ビットの値で埋めます。
※ instanceofは参照データ型の値の型をチェックする演算子です
※ 論理値に対する&と&&の違いは&&が短絡的評価を行うことです
※ ?:は 条件式 ? 真の場合の値 : 偽の場合の値 の様な書式で使います
例 System.out.println( a%2==0
? "aは偶数"
: "aは奇数"
);
※ C言語のカンマ演算子に対応するjavaの演算子はありません
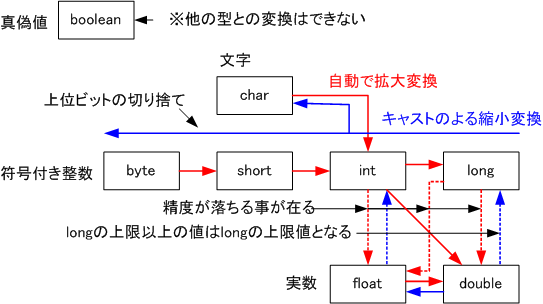
型が異なるデータの演算では自動的に精度の高い方の型に揃えて演算が行われる。
ただし、boolean型は他の型と変換できない。
byte>short>int>long>float>double および char>int のデータ変換は必要に応じて自動的に行われる。
byte>short>int>longの拡大変換では符号を保って(0または1で上位ビットを埋める)変換する。
charからintへの変換は0で上位ビットを埋めて変換する。
long型からfloat, double あるいは intからfloatへの変換では精度が落ちる場合がある
/*このプログラムのファイル名はCast.java*/
public class Cast{
static public void main(String argv[]){
byte b=65;
short s=b;
//char c=b;はコンパイルエラー
//char c=s;はコンパイルエラー
int i=s;
long l=i;
float f=l;
double d=f;
System.out.println("f="+f);
char c='B';
i=c;//charからintへの自動変換は可
System.out.println("i="+i);
}
}
/* 実行結果
f=65.0
i=66
*/
拡大変換の逆の変換はキャストによる変換が必要。
long>int>short>byteの向きに縮小変換を行う場合は上位ビットを切り捨てるため、値の符号が変ることがある。
整数の範囲を超えた実数型から整数型への変換では、例えば整数の上限以上の値は最大値に変換される。
/*このプログラムのファイル名はCast2.java*/
public class Cast2{
static public void main(String argv[]){
int i=-129;//負の数
byte b=(byte)i;//この型変換で正の数に化ける
System.out.println("b="+b);
}
}
/* 実行結果
b=127
*/
[目次]
C言語ではデータを記憶するメモリーとしてスタック領域,静的領域,ヒープ領域が自由に使えます。配列や構造体を記憶する場所も,この3領域全てが使えます。しかし,java言語ではこれを制限して自動的なメモリー開放のガべージコレクション機能を提供します。
例えば,C言語では配列や構造体のデータをスタック領域に記憶できますが,java言語ではスタック領域に割り当てできるのは基本データ型と参照データ型(C言語のポインタ型に対応する型)の変数のみです。インスタンス(インスタンスのフィールド(メンバ変数)を含む)はヒープ領域にのみ記憶できます。
参照(Wiki)は他の場所にあるインスタンスを指して,そのインスタンスを参照するのに使えるものです。例えはC言語のポインター変数はアドレスを記憶し、ポインター変数からの間接参照で、そのアドレスのデータを読み書きしたり、関数の機械語が記憶されていれば、その関数を呼びだして実行することが可能です。C言語のメモリーアドレスを記憶するポインターは参照を実現する1つの実装方法です。
Java言語では参照データ型の変数にインスタンスを参照するための値を記憶します。この変数を使った間接参照によりインスタンスのフィールドを読み書きしたり、メソッドを実行したりします。
しかし、C言語のポインターとは違い,java言語の参照からインスタンスが格納されたメモリーアドレスを読み出したり、参照変数に数値でアドレスを代入したりすることは出来ません。
※java言語では参照の具体的な実装方法を定めていないので、自動ガベージコレクションに適した実装を行うことも可能になります。
オブジェクトの生成と利用は次の手順で行います。
※javaの変数は基本データ型と参照データ型の値しか記憶できません。
java言語ではインスタンスを直接記憶する変数は作れません。
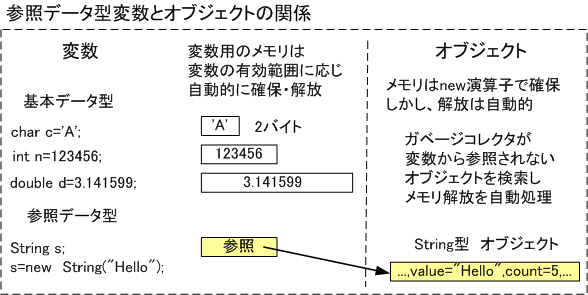
文字列「Hello」の参照を参照データ型変数sに代入する文を示します。
String s; //String型のインスタンスを参照する参照データ型変数sの定義
s=new String("Hello"); // sへ「Hello」で初期化されたString型インスタンスへの参照を代入
次の図のように変数はスタック領域に割り当てられますが,インスタンスなどのオブジェクトはヒープ領域に記憶されます。スタック上の参照型変数から参照をたどって,たどることのできたインスタンスは使用中と判定できます。たどれなかったインスタンスは使われていないと判定でき,自動的なメモリー開放を行います。
次の表はjavaとC言語で変数の参照方法を比較したものです。javaは変数にインスタンスを記憶できない、変数の参照を取得できないといった制限が在る。しかし、この制限の結果としてデータの参照方法はC言語に比べて、とても単純になる。
| 変数 | 変数の値 | 変数からの間接参照 |
| java言語の場合 | ||
| 基本データ型 変数 |
機種依存が無いように一意に 定義された基本データ型の値 |
|
| 参照データ型 変数 |
インスタンスの参照値 (変数やクラスの参照は不可) |
メンバを間接参照する演算子は「.」 |
| C/C++言語の場合 | ||
| 変数 | 基本データ型の値、機種依存あり 配列、構造体、オブジェクト メンバを参照する演算子は「.」 |
(整数をポインター型にキャスト変換可能) |
| ポインター型 変数 |
メモリーアドレス |
間接参照の演算子は「*」 メンバを間接参照する演算子は「->」 |
C/C++言語には、配列や構造体などの構造を持つデータ型が有ります。次のプログラム例の様にデータは変数で直接扱える他に間接的にポインタ変数を用いて利用することもできます。この為にC/C++では メンバを参照する演算子に、メンバアクセス演算子「.」と間接メンバアクセス演算子「−>」の2つが用意されています。
/*C言語の構造体のサンプル*/
#include<stdio.h>
#include<stdlib.h>
typedef struct Complex /*複素数の構造体*/
{
double re;/*実部*/
double im;/*虚部*/
}complex;
int main(void)
{
complex z;/*自動変数なのでスタックにメモリ割り当てされる*/
complex *p;/*ポインタ変数*/
/*直接参照の変数を使う場合*/
z.re=1; z.im=0;/*変数から直接参照して成分へ代入*/
printf("z=(%3.1lf,%3.1lf)\n",z.re,z.im);/*直接に成分を読む*/
/*ブロックから出るとスタック上の変数zのメモリ領域は解放される*/
/*間接参照のポインタ変数を使う場合*/
p=(complex*)malloc(sizeof(complex));/*動的メモリ確保*/
p->re=1; p->im=0;/*ポインタ変数から間接参照し成分へ代入*/
printf("*p=(%3.1lf,%3.1lf)\n",p->re,p->im);/*間接に成分を読む*/
free(p);/*構造体を格納したヒープ上のメモリを解放する*/
return 0;
}
これに対してjavaの変数に格納できるのは基本データ型の値とインスタンスの参照のみです。
変数のデータ型は基本データ型以外はインスタンスの参照を格納する変数です。従って、変数の宣言にC言語のようなポインタ子「*」は使いません。
インスタンスのメンバ(要素)の参照は全て間接参照で行われるのでC言語のようにメンバアクセス演算子を区別する必要はありません。従って、javaでは ドット演算子「.」のみを使います。
| C言語 | java言語 |
|
ポインタ演算子「*」
間接参照演算子「*」 |
ない |
| メンバアクセス演算子「.」 | ない |
| 間接メンバアクセス演算子「−>」 | ドット演算子「.」 |
上の例をjavaで書き直してみます。javaでは変数に構造体を代入する形は不可能なので、「ポインタを用いた場合」に対応するプログラムを示します。
Cの構造体はjavaではクラス(class)で書けます
| Complex |
| <<変数;フィールド>> +re:double +im:double |
| <<関数;メソッド>> +Complex( r: double, i: double) |
このクラスのインスタンスを使う形でプログラムを書くと次のようになります
/*このプログラムのファイル名はComplexTest.java*/
class Complex
{
double re;//実部
double im;//虚部
//初期化の為の関数。コンストラクタと言う
public Complex(double r,double i)
{
re=r;
im=i;
}
}
public class ComplexTest
{
static public void main(String arg[])
{
Complex p;//参照データ型の変数pの宣言
//Cプログラムでの対応する記述は
//complex *p;
p=new Complex(1,0);//メモリ確保+コンストラクタで初期化+参照のpへの代入
//Cプログラムでの対応する記述は
//p=(complex*)malloc(sizeof(complex));
//p->re=1;p->im=0;
System.out.println("p=("+p.re+","+p.im+")");
//p.re p.im の部分のCプログラムでの対応する記述は
//p->re p->im
//C言語のfree(p)に対応する文は無い
//ブロックから出るとスタック上の変数pの領域は解放される
//ヒープ上にあるインスタンスのメモリ領域は、
//何処からも参照されなくなる。
//ガベージコレクタにより何処からも参照されないインスタンスのメモリ解放が行われる。
}
}
※javaの参照データ型の変数はCのポインタ変数に対応するものであることを忘れないでください。
プログラム実行中に記憶場所が必要になった時にヒープ領域から空いているメモリーを見つけて確保することをメモリの動的確保といいます。確保したメモリが用済みになった場合は確保した領域を空けます。これをメモリ開放といいます。メモリが足りなくなると新たなメモリ確保ができなくなったり、ディスクスワップが多発しプログラムの実行が極端に遅くなることがあるので、用済みのメモリは必ず開放するのが常識です。
現在のOSはマルチタスクの機能を持ち多数のプログラムを時分割で同時に実行しています。この為、、実行中のプログラムの中にメモリーを多量に食いつぶすモノがあると、他のプログラムの動作に悪い影響を与えてしまいます。プログラムで確保したメモリは必ずそのプログラム内で細めに開放してください。
※メモリースワップ:現代のOSは計算機のメモリー管理において、使われることの少ないメモリーの内容をHDDなどの2次記憶装置に一時的に退避させ、他の目的にそのメモリーを割り当てる機能を持っています。HDDなどの二次記憶装置のアクセスはメモリーに比較すれば100万倍ぐらい遅いのでメモリースワップが多発するとプログラムの動作が止まって見えるほど遅くなります。
Javaは「ガベージコレクション」と呼ばれる自動的なメモリ開放の仕組みをもっています。全ての参照型の変数からの参照のつながりを辿って、辿れないオブジェクトは使えないオブジェクトです。ガベージコレクションは、そのオブジェクトのメモリ領域を開放し、使用メモリ領域を移動して隙間をつめることで、連続した空きメモリを作ります。同時に参照も移動後の新しい場所を示すように書き換えます。
参照変数=>オブジェクトA オブジェクトAのフィールド(メンバ変数)からの参照=>オブジェクトBといった参照をすべて辿ってもたどり着けないオブジェクトがガベージコレクションの対象になります。ガベージコレクションはメモリーが不足したときに並列処理で行われますが、Systemクラスのgcメソッドを呼ぶことで明示的にガベージコレクションを実行できます。
System.gc( );
メモリーが足りなくなってからガベージコレクションを実行すると処理時間を取られてプログラムの動作が一時的に停滞することがあります。こまめにガベージコレクションを行うことで、プログラムをスムーズに実行したい場合にこのgcメソッドを使います。
メモリーを使っていない筈なのに、空きメモリーが次第に減少していく状況になることがあります。この状況をメモリー・リークが起きているといいます。空きメモリーが少なくなると新たなメモリー割り当てができなくなりシステムの動作が遅くなったり停止したりします。
0)OSに問題が在ってメモリ解放が不完全な場合。
これは最近は無いはず。多くのOSはプログラムが終了すれば、そのプログラムが使っていたメモリーを自動的に解放します
。これに期待して、メモリー解放を行わないプログラムを作ることで、メモリー解放の煩わしさや間違いを避けようとする人もいます。
しかし、これは短時間で終了する一時的なプログラムでしか許されない手法です。
1)プログラムが確保したメモリーを解放せず、新しいメモリー割り当てを要求し続ける場合。
これはプログラムが本当に必要とするメモリーなら仕方がないのですが、不要な物なら解放しなければいけません。特に長時間動作するようなプログラムの場合は計算機のメモリーを使い切る恐れがあります。
※ほとんどの場合に確保したメモリーは解放を行っていても、一つだけ解放を忘れているということもあります。長い時間にわたって解放せずに、新たな取得を続けると、メモリーを少しづつ食いつぶすことになってしまいます。しかも長時間動かさないと異常に気がつかないかもしれません。
C言語では、確保したメモリ領域の先頭番地をポインタ変数に代入し記憶しますが、解放を忘れて、新たに取得したメモリーの番地でポインタ変数を上書きしてしまうとこの状態になります。後で気付いても、番地情報がないとメモリ解放はできません。
(注)解放忘れを避けようとして2重3重に同じメモリーを解放してしまう間違いもあります。さらに解放したメモリーにポインターで書きこんでしまうこともあり得ます。ポインタを使ったPascalやC/C++のプログラミングでは メモリー確保と解放に関係した問題がよく起きます。
C言語のポインターは番地を格納するデータ型で数値としても代入や演算が可能なため、その値を変更すれば、どんな番地のメモリーでも参照できます。ただ、できることが増えれば間違いも多くなります。さらに、他人の書いたプログラムの場合にはなにをされるか分からないといった危険性ももたらします。言語処理系の中にはプログラムを実行するときの機械語やデータを格納する場所をわざと入れ変えて、何が何処にあるかを分かりにくくするといったことを行うものがあります。これはアドレスを知られるとハッキングで狙われるからです。
Javaが用意する参照データ型はC言語のポインターの様に数値として値を取り出したり、数値の代入や四則演算を行うことは許されません。 さらにオブジェクトを参照するためのデータしか格納できません。
配列と文字列についてプログラム例を示します。自分の環境で実行してみて下さい。
| 配列 int[ ] |
| <<フィールド>> +length:int −要素データ列 |
| <<メソッド>> +配列の初期化 +添え字を用いたデータの参照 ※ここで添え字はint型 |
配列のデータが格納されたフィールド(メンバ変数)は非公開です。その代わりに[添え字]を用いたデータ参照のための公開メソッドが用意されています。ここで[ ]は一見メソッドには見えませんが、添え字として範囲外の値を与えると、チェックされて実行時エラーとなるので添え字の範囲を確認する処理が行われているのがわかります。また、配列の公開フィールドとして配列の要素数が用意されています。これは便利です。詳細は下記で
http://www.y-adagio.com/public/standards/tr_javalang/10.doc.htm
(注)フィールドlengthは値を読み出せますが変更はできない定数です。変更しようとするとコンパイルエラーとなる。
/*
このファイルはArrayTest.java
n[0]=1,n[1]=1でn[i]=n[i-1]+n[i-2]をi=10まで計算するプログラム
*/
public class ArrayTest{
static public void main(String arg[]){
int n[];//一次元配列を参照する変数n (要素数は指定できません)
//int n[11];のような書き方はできない
int i;
n=new int[11];//11個のint型データの配列をメモリに確保し参照をnに代入。0〜10で11個に注意
for(i=0;i<n.length;i++){//配列nの要素数は成分lengthに入っている
if(i==0){
n[i]=1;
}else if(i==1){
n[i]=1;
}else{
n[i]=n[i-1]+n[i-2];
}
System.out.println("n["+i+"]="+n[i]);
}
//メモリー開放は自動的に行われる
}
}
Cの配列とよく似ていますが作り方が異なります。さらにJavaの配列では要素数を配列自身が成分として保持しているので便利です。
要素の参照がメソッド(メンバ関数)で行われるので,添え字の範囲がチェックされます。添え字の値が範囲外の場合,実行時エラーが報告されます。
文字列のデータを格納するインスタンスの代表的なクラスにStringがあります。Stringは変更しない文字列の記憶につかうもので,文字列の編集を行う場合はStringBufferクラスのインスタンスを用いてください。
| String |
| <<フィールド>> −文字列データ .... |
| <<メソッド>> +String() 空の文字列を生成 +String(s:String) 文字列sをコピーして初期化 .... +charAt(index:int):char index番目の文字を戻す +length():int 文字数を返す +indexOf(s:String):int 文字列sが最初に現れる位置を戻す ..... .... |
Stringの公開メソッドは非常に多い。文字列検索のメソッドも多数ある。詳細は下記を参照
http://docs.oracle.com/javase/jp/6/api/java/lang/String.html
/*このファイルはStringTest.java*/
public class StringTest{
static public void main(String arg[]){
String one=new String("One ");//String one="One ";と簡略化できる
String two=new String("Two ");
String three=new String("Tree");
String s,t;
//
System.out.println("one="+one);
System.out.println("two="+two);
System.out.println("three="+three);
//
s=one+two+three;//文字列の足し算は文字列の結合
System.out.println("s=one+two+three;//文字列の足し算は文字列の結合");
System.out.println("s="+s);
System.out.println("文字数s.length()は"+s.length());//文字列の長さはlength()関数でget
//
t=s;//tにもsと同じ場所を代入
System.out.println("t=s;を実行するとt,sは同じ実体を参照する");
System.out.println("s="+s);
System.out.println("t="+t);
//
t=t+" Four";//文字列の足し算はその文字を長くするのではなく別に作る
System.out.println("t=t+\" Four\";//文字列の足し算では別に実体が作られる");//「"」は「\"」
System.out.println("s="+s);
System.out.println("t="+t);
System.out.println("t,sは異なる実体を参照している");
}
}
Stringのインスタンスは生成後に内容を変更できない。
頻繁に変更する文字列はStringBufferを用いること
Stringのインスタンスとして作った文字列オブジェクトに対しては足し算の演算子で文字列の結合ができます。ここで注意してほしいのは、結合された文字列のオブジェクトは別の場所に新しく作られることです。つまり結合前のオブジェクトA,Bと新しいオブジェクトA+Bができることになります。
String A=new String("123");//文字列「123」のStringオブジェクトを生成し、その場所をAに記憶
String B=new String("456");//文字列「456」のStringオブジェクトを生成し、その場所をBに記憶
A=A+B;//ここで、文字列「123456」のStringオブジェクトを生成し、その場所をAに上書きして記憶
//文字列「123」のStringオブジェクトは何処からも参照されないのでガベージコレクションの対象になる
プログラムの中で文字列の足し算を繰り返し行うとメモリが足りなくなってガベージコレクションが頻繁に行われます。これはJavaのプログラムが遅くなる原因となります。 1文字づつ追加して長い文字列を作るような処理ではStringBufferを用いてください。
StringBuffer A=new StringBuffer("123");//文字列「123」のStringBufferオブジェクトを生成し、その場所をAに記憶
String B=new String("456");//文字列「456」のStringオブジェクトを生成し、その場所をBに記憶
A.append(B);//ここで、StringBufferオブジェクトの中身「123」に「456」を追加して、中身を「123456」に更新する。
写経課題です下記のプログラムを課題3初期ファイルに書き足して提出してください。
public class P3
{
public static void main(String args[])
{
byte ib=0x12;
short is=0x1234;
int ii=0x12345678;
long il=0x123456789ABCDEF0L; /* longのリテラル 最後がL */
System.out.println("ib="+ib);
System.out.println("is="+is);
System.out.println("ii="+ii);
System.out.println("il="+il);
System.out.println();
boolean b=true;
char c='鹿';
float f=(float)Math.PI;;
double d=Math.PI;
System.out.println("b="+b);
System.out.println("c="+c);
System.out.println("f="+f);
System.out.println("d="+d);
System.out.println();
int array[ ]=new int[2]; /* int array[2]ではエラー */
array[0]=1;
array[1]=2;
System.out.println("arrayの要素数="+array.length);
System.out.println("array[0]="+array[0]);
System.out.println("array[1]="+array[1]);
}
}
実行結果は下記のようになります。
自分のプログラムが同じ結果になるか確認してください。
ib=18 is=4660 ii=305419896 il=1311768467463790320 b=true c=鹿 f=3.1415927 d=3.141592653589793 arrayの要素数=2 array[0]=1 array[1]=2
[目次]