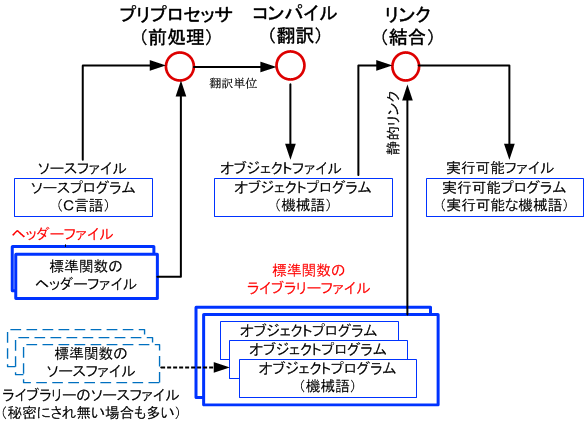
C言語自体には文字を書き出す機能さえも用意されていない。変数を定義し、四則演算を記述し、条件分岐や繰り返しの構文を用意し、関数を部品としてプログラムを記述し組み立てる仕組み,と,多数のデータを効率よく記憶し処理するための配列や構造体などを用意しただけである。
文字を書き出すといった,基本的な機能はC言語の標準関数として用意されている。標準関数はC言語やアセンブリ言語で記述され、それらを翻訳した機械語の関数をまとめてライブラリ・ファイルとして提供される。 ライブラリから必要な関数をプログラムにリンクすることで,これらの機能を利用する。
●標準関数
プログラミングで誰もが必要とするような機能を提供するために、標準で用意された関数。 標準関数の呼び出しに必要な関数のプロトタイプ宣言は以下のようなヘッダーファイルの形で用意されている。標準関数を利用するプログラムでは,プロトタイプ宣言を追加するために前処理でヘッダーファイルをインクルードする。
●プリプロセッサ
C言語ではコンパイルする前に、プリプロセッサによりプログラムのテキスト(ソースコード)を前処理する。主な機能は、
プログラムを作るとき全ての機能を1から作るのは非現実的な労力を必要とする。現在のプログラミングは、過去のプログラム資産や他人の作った関数を 有効活用することで初めて可能になっている。
C言語では、関数ライブラリー・ファイルから自分のプログラムに必要な関数を取り込んで結合し利用する仕組みが提供される。この取り込みと結合の処理をリンクと言う。
※標準関数で足りない場合、有用な関数のライブラリーを購入して利用することも多い。言語処理系を差別化するものとしてGUIを実現するための関数ライブラリーが用意されることも多い。
プログラムでは、標準関数を呼ぶ記述の前には関数プロトタイプ宣言が必要になる。そこで、標準関数のプロトタイプ宣言をまとめて記述したヘッダーファ イルが用意されている。プリプロセッサにより、このへッダーファイルの中身を#include命令でソースコードに取り込んでから、コンパイルすることで,関数の呼び出し部分を機械語に変翻訳できる。
次の,リンク処理では,こうして作られたオブジェクトファイルに、呼ばれる側の標準関数などをライブラリから取り込んで結合し,実行可能ファイルを作る。
以下にstdio.h math.h string.h stdlib.h の4個のヘッダーファイルを使う標準関数を紹介 する。
入出力の標準関数についてプロトタイプ宣言などを集めたヘッダーファイル
|
|
|
| 標準入出力 | |
| int printf(const char *format,...) | 書式付き出力 |
| int scanf(const char *format,...) | 書式付き入力 |
| int putchar(int c) | 一文字出力 |
| int getchar(void) | 一文字入力 |
| int puts(const char *s) | 文字列出力 |
| char* gets(char *s) | 文字列入力 sは文字列を入れる場所 |
| ファイル操作 | |
| FILE *open(cost char*fname,const char *mode) | ファイルのオープン |
| int fclose(FILE *stream) | ファイルのクローズ |
| int fflush(FILE *stream) | ファイルバッファのフラッシュ |
| int fprintf(FILE*stream, const char *format,...) | ファイルへの書式付き出力 |
| int fscanf(FILE*stream,const char *format,...) | ファイルからの書式付き入力 |
|
int putc(int c,FILE *stream) int fputc(int c,FILE*stream)int |
ファイルへの一文字出力 |
|
getc(FILE*stream) int fgetc(FILE*stream) |
ファイルからの一文字入力 |
| int fputs(const char*s,FILE *stream) | |
| char* fgets(const char*s,int n,FILE *stream) | |
|
........ |
指数や対数関数、三角関数などの初等関数を使うためのヘッダーファイル
(注:リンク処理では数値計算用ライブラリーファイルの指定を必要とする処理系もある)
|
|
|
|
三角関数 |
|
| double acos(double x) | arccos(x) 逆三角関数 |
| double asin(double x) | arcsin(x) |
| double atan(double t) | arctan(t) |
| double atan2(double y,double x) | arctan(y/x) 正負のx,yや x=0に対応 |
| double cos(double x) | cos(x) 三角関数 |
| double sin(double x) | sin(x) ={exp(ix)-exp(-ix)}/2i |
| double tan(double x) | tan(x) |
| double cosh(double x) | cosh(x) 双曲線関数 |
| double sinh(double x) | sinh(x) ={exp(x)-exp(-x)}/2 |
| double tanh(double x) | tanh(x) |
|
指数、対数 |
|
| doublu exp(double x) | exp(x) |
| doublu log(double x) | 自然対数 |
| doublu log10(double x) | 常用対数 |
| double pow(double x,double y) | xy |
| double ldexp(double x,int n) | x*2n |
| double sqrt(double x) | 平方根 |
|
その他 |
|
| double fabs(double x) | 絶対値 ※ |
| double ceil(double x) | xより小さくない最少の整数値 |
| double floor(double x) | xより大きくない最大の整数値 |
|
........ |
※名前の衝突
整数の絶対値を得る関数
int abs(int)
があるため実数に対しては同じ名前の関数を作れない。そこでfを付けてfabsと区別している。
文字の分類や変換に関する標準関数のヘッダーファイル。
処理系の文字コードに依存するような処理は、汎用性や移植性を考慮して用意された標準関数を用いることで依存性を回避する。
|
|
|
|
文字の分類 |
|
| int isalnum(int) | 英数字かどうかの判別 |
| int isalpha(int) | 英字かどうかの判別 |
| int isspace(int) | 空白類文字かどうかの判別 |
| ........... | この他にも色々ある |
| 文字の変換 | |
| int tolower(int) | 小文字に変換 |
| int toupper(int) | 大文字に変換 |
| .......... | この他にも色々ある |
1文字づつ読み込んで、読み込んだ文字(入力)に応じて状態をかえながら、単語の終端を判定して連続したアルファベットを1つの単語として出力するプログラムを紹介します。
次の図は状態遷移図と呼ばれています。 単語外と単語内の2つの状態を入力結果に応じて矢印のように遷移します。遷移の条件となる入力と遷移における動作を「入力/動作」の型で示しました。
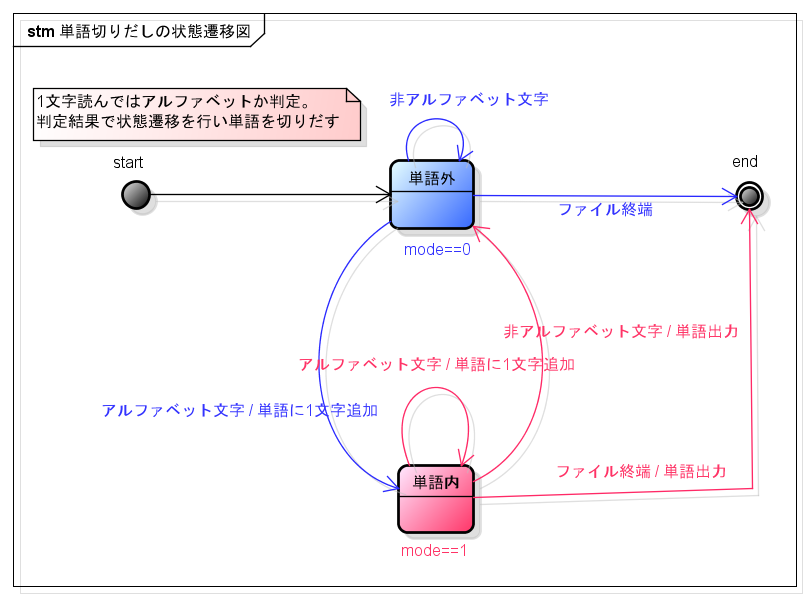
※このプログラムは大文字と小文字の区別はしないことにして、全てを小文字に変換すます。また、行末のハイフン等も単語の切れ目としてしまいます。2バイトの文字コードが含まれると正しく動きません。
#include<stdio.h>
#include<ctype.h>
/*
標準入力から文字列を読み込んで
連続するアルファベットを単語として切りだし
(大文字は小文字に全て変換する)
標準出力へ改行で区切って出力する
*/
int main(void)
{
char buffer[256],index=0;
int c,i;
int mode=0;/*文字列の内外を示す状態変数*/
while(1){
c=getchar();
if(mode==0){/*単語外の状態のとき*/
if(c==EOF) break;
if(isalpha(c)){/*アルファベットなら*/
mode=1;/*単語内の状態に遷移*/
index=0;
c=tolower(c);/*全て小文字に変換*/
buffer[index++]=(char)c;
}
}else{/*単語内の状態のとき*/
if(c==EOF){
for(i=0;i<index;i++)
putchar(buffer[i]);
putchar('\n');
break;
}
if(isalpha(c)){/*アルファベットかチェック*/
c=tolower(c);/*全て小文字に変換*/
buffer[index++]=(char)c;
if(255<index){
printf("BUFFER OVERFLOW");
break;
}
}else{/*アルファベットでなければ*/
for(i=0;i<index;i++)
putchar(buffer[i]);
putchar('\n');
mode=0;/*単語外の状態に遷移*/
}
}
}
return 0;
}
※('A'<=c && c<='Z')||('a'<=c && c<='z') の様な条件判定では計算機システムの文字コードがASCIIコード以外の場合に正しくアルファベットを判定できない。たとえばEBCDIC(エビシディック)ではアルファベッドに対応する文字コードに隙間が有り、'A'から’Z’の間には文字に対応しない値も含まれている。
文字列処理の標準関数のヘッダーファイル。
|
|
|
| size_t strlen(char *s) |
文字列の長さを戻す ポインタsから始まる文字列の長さを戻す。文字列終端の\0を含まない size_t型はsizeof()演算子が戻すデータ型でunsigned intまたはunsigned longとなる。計算機の環境に対応する為にこのように別名が使われる。 |
|
char *strcpy( char *s, const char *s2) |
文字列 のコピー ポインタs2から始まる文字列をポインタsからのメモリーにコピーする。※sが示すメモリー領域が文字列を格納できる大きさであるか注意。戻り値はs |
|
char *strcat( char *s, const char *s2) |
文字列の結合 ポインタs2から始まる文字列をポインタsから始まる文字列のあとにコピーして書き加える。※sが示すメモリー領域が結合された文字列を格納できる大きさであるか注意。戻り値はs |
|
int strcmp( const char*s, const char *s2) |
文字列の比較 sとs2から始まる文字列を先頭から比較し、辞書順でs2<sなら正、s2>sなら負, s==s2でゼロの値を戻す。 |
| ........... | この他にも色々ある |
|
|
|
| 文字列の数値への変換や逆変換 | |
| int atoi(cost char*s) | ascii string to integer |
| long atol(cost char*s) | ascii string to long integer |
| double atof(const char*s) | ascii string to floating-point number |
| ........... | この他にも色々ある |
| 記憶域管理 | メモリの確保や解放、データのコピーなどの標準関数 |
| void*malloc(size_t size) |
memory allocation size バイトの連続したメモリを確保 |
| void free(void *p) | pから確保されたメモリを解放 |
| .......... | この他にも色々ある |
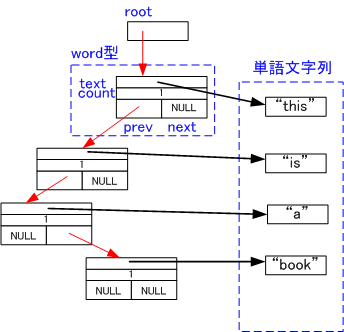
単語をアルファベット順に並べ替えるプログラム。アルファベット順で前の単語はprev側に追加、後の単語はnext側に追加する二分木と呼ばれるデータ構造を使い、単語を追加していくことで並べ替えを同時に行う。 同じ単語の場合は出現数をカウントアップしている。
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
typedef struct WORD{
char *text;
int count;
struct WORD *prev;
struct WORD *next;
} word;
word* newWord(char*str)
{
word* p;
p=(word*)malloc(sizeof(word));/*wordのメモリ領域を取得*/
p->text=(char*)malloc(strlen(str)+1);/*文字列を格納する領域を取得*/
strcpy(p->text,str);/*文字列をコピー*/
p->count=1;
p->prev=NULL;
p->next=NULL;
return p;
}
/*二分木の根*/
word *root=NULL;
/*ソートしながら二分木へ文字列を追加する関数*/
void addWord(word**p,char*str)/*再帰呼び出しと2重ポインタが判り難いかも*/
{
int r;
if(*p==NULL){
*p=newWord(str);
return;
}
r=strcmp(str,(*p)->text);/*文字列の比較*/
if(0<r){/*next側に追加*/
addWord(&((*p)->next),str);
}else if(r==0){/*見つけたので追加の必要なし*/
(*p)->count++;
}else{/*prev側に追加*/
addWord(&((*p)->prev),str);
}
return;
}
/*リストの打ち出し、こちらも再帰を使っている*/
void printAll(word *p) {
if(p==NULL)return;
printAll(p->prev);
printf("出現個数\t%d\t%s\n",p->count,p->text);
printAll(p->next);
return;
}
int main(void)
{
char buffer[256];
while(scanf("%255s",buffer)==1){
addWord(&root,buffer);
}
printAll(root);
return 0;
}
[メモ]
短いプログラムだが単語切りだしプログラムと組み合わせれば、英文の単語出現率を調べることも可能。
例として、不思議の国のアリスから単語の使用頻度の高い順に10位までを示す.。
| 1818 | the |
| 940 | and |
| 809 | to |
| 690 | a |
| 631 | of |
| 610 | it |
| 553 | she |
| 545 | i |
| 481 | you |
| 462 | said |
C言語のソースプログラムは前処理を行ってから翻訳が行われる。
前処理ではプリプロセッサ命令文に従ってテキストの挿入や置き換えを行う。 プリプロセッサ命令文は行の先頭から「#」で始まる。この部分はCプログラムの命令文ではない。
この行を指定されたファイルのテキストで置き換える。
< >で囲んで指定する
ヘッダーファイルが置かれる標準の場所からファイルを捜す
””で囲んで指定する
ソースファイルが置かれる場所からファイルを捜す(捜す場所は処理系依存)
文字列の置き換えを指示する。
#define NUM 100
これは、これ以後のテキストで文字列NUMを100に置き換えることを指示
#define MAX(a,b) (((a)>(b))?(a):(b))
これは 関数形式マクロと呼ばれるもので このパターンの文字列を置き換える。あたかも関数の様に使えるマクロ
c=MAX(10+5,x+a);
は
c=(((10+5)>(x+a))?(10+5):(x+a));
に置き換えられる。
値が0(偽)ならendifまでを削除。
#if 〜#else〜#endif
の形でどちらかを選択する形にもできる
#ifdef〜
でマクロの定義の有無で分岐することも可能
虫取り(プログラムのミスを取り除く)や開発中の動作確認用のプログラムをON/OFFする例
/*虫取り用 プログラム完成時にDEBUGを0にする*/
#define DEBUG 1
.....
for(i=0;i<10;i++){
#if DEBUG
printf("a[%d]=%d",i,a[i]);/*計算に使うデータを全て書き出す*/
#endif
sum+=a[i];
}
....
#include<stdio.h>
int main(void)
{
printf("このプログラムは%s にコンパイルしました",__DATE__);
printf("ソースファイルは%s ここは%d行目です\n",__FILE__,__LINE__);
return 0;
}
プリプロセスだけを実行すると以下のように置き換わります。
.....stdio.hの中身が沢山あった後に...
int main(void)
{
printf("このプログラムは%s にコンパイルしました","Jul 17 2008");
printf("ソースファイルは%s ここは%d行目です\n","test.c",5);
return 0;
}
コンパイルを行った日付や元のソースファイル名や行番号を実行可能プログラムに組み込むことが可能になります。