C言語は構造化言語といわれていますが、この構造化とは何でしょうか?。私はプログラムを無秩序なものから構造が見て取れるようなものにすることと捕らえていますが、具体的には次のようになります
1)プログラムが複雑化すると、その中で命令の実行順番を様々に変更することが必要になります。ここで、処理の順番を自由に変更できるgoto文をつかうと処理の順番が人間には把握できないようなものになりかねません。ダイクストラ(Edsger Wybe Dijkstra)は構造化定理で順次、分岐、繰り返しの制御構造を用いればgoto文を使わずにプログラムを記述できることを示し、goto文を使わずにこれらの制御構造を利用することを推奨しました。C言語ではif,while、forなどの制御構文を使うことでプログラムの実行順番 の把握が容易になります。
2)プログラムが大規模化すると、プログラムの全てを一度に把握することは不可能になります。この様な場合の対応手段は一度に把握が必要な範囲を小さくすることです。まずプログラムに要求される仕事を幾つかのサブプログラムに分け、個々のサブプログラムがきちんと役割を果たせば、それを組み合わせた全体が目的の動作をするようにします。
もちろん、サブプログラムの作成では他のサブプログラムやその組み合わせ方などは考える必要が無いようにして、要求された仕事だけ考えれば済むようにしなければいけません。これができれば個々のサブプログラムを他のプログラマに任せることも可能になります。C言語は 関数によってこの様なサブプログラムの作成を容易に行える代表的な構造化言語と言えます。このことについて以下で解説します
プログラムをサブプログラムに分けて考えるためにはサブプログラムの役割と、それに関わる入出力データを明確にしなければなりません。ここでは試験の成績から統計データを計算するプログラムを考えてみることにします。
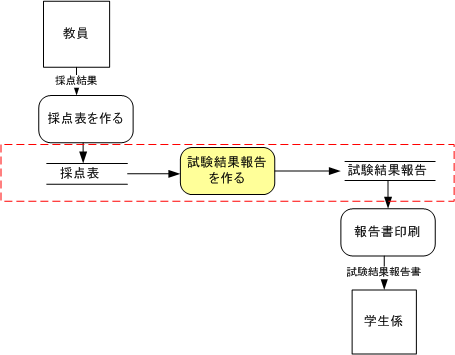
例として成績報告書作成を計算機で支援するシステムを考えてみましょう。まずは、必要な処理を人間が行う場合の手順を調べます。
あわせて、各処理で使われるデータの形も調べます。
{ }で囲んだ項目はデータが繰り返し現れることを示し、( )で囲んだ部分はオプションで
試験結果報告書=科目名+担当者名+平均点+標準偏差+{学生の得点}
学生の得点=学籍番号+学生氏名+出欠+(得点+偏差値)
科目名、担当者名、学生氏名は50文字以内
学籍番号は10文字以内
出欠はy/nの1文字 欠席:nの場合は得点と偏差値は無い
得点は0〜100の範囲の整数
偏差値は実数
プログラムを使うことでどのようにするか考えてみます。処理1,2は直接報告書に書くのを止めてエクセルなどの既存ソフトで 採点表をまず作ることにします。ここで作るプログラムは採点表ファイルから試験結果報告ファイルを作るまでを守備範囲とします。試験結果報告ファイルを印刷して報告書を作成する部分も既存ソフトを使うことで可能なので 守備範囲から除きます。
デ・マルコがシステムの構造化分析設計のために使った図で、データを処理するプロセスを円で表し、プロセスへの入出力データを線で表します。二重線 はファイルです。四角形は考察範囲の外にあるプロセスです。
1)プログラムの守備範囲だけを取り出せば次のようになります。
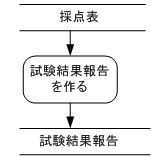
2)プロセスを段階的に詳細化
上のプロセスを小さなプロセスに分けて設計してみました。構造化分析設計では関数の仕様にできるほど十分に詳細化された各プロセスに対しては関数の仕様書となるミニ仕様書を作成
します。
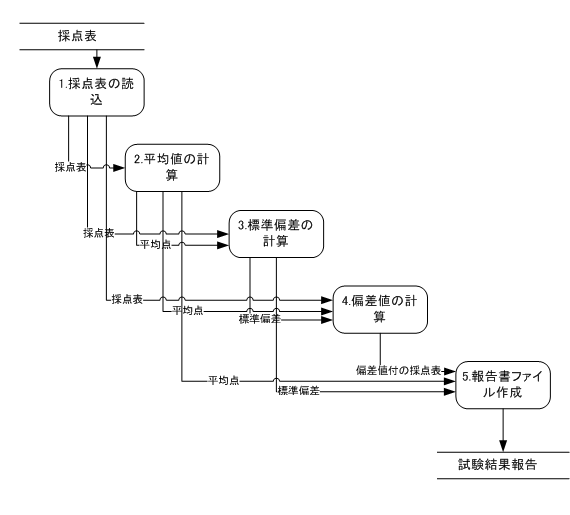
3)データ辞書
この図での各プロセスを関数で実装するわけですが、入出力データは関数の引数や戻り値となる重要な情報なのできちんと定義しておく必要があります。このためにデータ辞書を作ります。
採点表=科目名+担当者名+{学生の得点}
科目名、担当者名、学生氏名は50文字以内
※学生の得点は最大でも100項目です
学生の得点=学籍番号+学生氏名+出欠+(得点+偏差値)
学籍番号は10文字以内
出欠はy/nの1文字 欠席:nの場合は得点と偏差値は無い
得点は0〜100の範囲の整数
偏差値は実数
※偏差値は偏差値の計算で追加されます。
採点表は次のようなテキストファイルとします
プログラミング 水野 1123456 真志 y 90 1123457 聖治 y 74 1123458 敦詞 y 83 1123459 大輔 n 1123460 佳史 y 73 1123461 祐介 n 1123462 卓哉 y 78 1123463 直亮 y 60 1123464 政徳 y 48 1123465 裕一 n 1123466 翔 y 93 1123467 芳道 y 89 1123468 尚志 y 80 1123469 英武 y 60
試験結果報告は 統計データを追加した次の様なテキストファイルとします
科目名 プログラミング 担当者 水野 平均点 75.3 標準偏差 14.2 1123456 真志 y 90 60.3 1123457 聖治 y 74 49.1 1123458 敦詞 y 83 55.4 1123459 大輔 n 1123460 佳史 y 73 48.4 1123461 祐介 n 1123462 卓哉 y 78 51.9 1123463 直亮 y 60 39.3 1123464 政徳 y 48 30.8 1123465 裕一 n 1123466 翔 y 93 62.5 1123467 芳道 y 89 59.6 1123468 尚志 y 80 53.3 1123469 英武 y 60 39.3
1)データ構造
データ辞書を元にデータのプログラム上の表現形式を定めます
/*データ構造の定義*/
/*受験者の成績*/
typedef struct{
char gakusekiBangou[10];/*学籍番号*/
char name[50];/*氏名*/
char shuxtuseki;/*出欠 y/n */
int tokuten;/*得点*/
double hensachi;/*偏差値*/
} seiseki;
/*成績表*/
/*プログラムでは先にseisekiの定義が必要なので成績表の定義が後に書かれている*/
typedef struct{
char kamoku[50];/*科目名*/
char tantou[50];/*担当者名*/
seiseki list[100];/*最大で100なので無駄が多いが予め100個用意*/
} seisekiHyou;
2)関数
データ構造と各処理の仕様をもとに関数をプログラムします
/*各プロセスを実装した関数*/
/*採点表の読み込み*/
seisekiHyou *readSeiseki(
char* inputFilename, /*成績表ファイルの名前*/
seisekiHyou *work /*成績表のメモリを用意して渡す*/
)
{
int i,n;
FILE *input;
input=fopen(inputFilename,"r");
if(input==NULL){
printf("成績表ファイルが開けません");
exit(1);
}
fscanf(input,"%s",work->kamoku);
fscanf(input,"%s",work->tantou);
for(i=0;i<100;i++){
n=fscanf(input,"%s",work->list[i].gakusekiBangou);
if(n==EOF){
work->list[i].gakusekiBangou[0]='\0';
break;
}
fscanf(input,"%s",work->list[i].name);
do{
fscanf(input,"%c",&(work->list[i].shuxtuseki));
}while(work->list[i].shuxtuseki==' ');
if(work->list[i].shuxtuseki=='y'){
fscanf(input,"%d",&(work->list[i].tokuten));
}
}
fclose(input);
return work;
}
/*平均点の計算*/
double calcHeikinten(
seisekiHyou *seisekihyou
)
{
int i,count=0;
double sum=0;
for(i=0;i<100;i++){
if(seisekihyou->list[i].gakusekiBangou[0]=='\0')break;
if(seisekihyou->list[i].shuxtuseki!='y')continue;
sum+=seisekihyou->list[i].tokuten;
count++;
}
return sum/count;
}
/*標準偏差の計算*/
double calcHyoujyunhensa(
seisekiHyou *seisekihyou,
double heikinten
)
{
int i,count=0;
double r,sum=0;
for(i=0;i<100;i++){
if(seisekihyou->list[i].gakusekiBangou[0]=='\0')break;
if(seisekihyou->list[i].shuxtuseki!='y')continue;
r=seisekihyou->list[i].tokuten-heikinten;
sum+=r*r;/**/
count++;
}
return sqrt(sum/(count-1));
}
/*偏差値の計算*/
seisekiHyou *calcHensachi(
seisekiHyou *seisekihyou,
double heikinten,
double hyoujyunhensa
)
{
int i;
double r;
for(i=0;i<100;i++){
if(seisekihyou->list[i].gakusekiBangou[0]=='\0')break;
if(seisekihyou->list[i].shuxtuseki!='y')continue;
r=seisekihyou->list[i].tokuten-heikinten;
seisekihyou->list[i].hensachi=50+r/hyoujyunhensa*10;
}
return seisekihyou;
}
/*報告書ファイルの作成*/
void writeHoukokusho(
char *outputFilename,
seisekiHyou *seisekihyou,
double heikinten,
double hyoujyunHensa
)
{
int i;
FILE *output;
output=fopen(outputFilename,"w");
if(output==NULL){
printf("報告書ファイルが開けません");
exit(2);/*戻り値2でプログラムを強制終了*/
}
fprintf(output,"科目名 %s\n",seisekihyou->kamoku);
fprintf(output,"担当者 %s\n",seisekihyou->tantou);
fprintf(output,"平均点 %.1f\n",heikinten);
fprintf(output,"標準偏差 %.1f\n",hyoujyunHensa);
for(i=0;i<100;i++){
if(seisekihyou->list[i].gakusekiBangou[0]=='\0')break;
fprintf(output,"%s\t",seisekihyou->list[i].gakusekiBangou);
fprintf(output,"%s\t",seisekihyou->list[i].name);
/**/
if(seisekihyou->list[i].shuxtuseki=='y'){
fprintf(output,"%c\t",seisekihyou->list[i].shuxtuseki);
fprintf(output,"%d\t",seisekihyou->list[i].tokuten);
fprintf(output,"%.1f\n",seisekihyou->list[i].hensachi);
}else{
fprintf(output,"%c\n",seisekihyou->list[i].shuxtuseki);
}
}
fclose(output);
return;
}
3)main関数
データフロー図に従って各関数を連携し目的の処理を行います。
#include<stdio.h>
#include<stdlib.h>
#include<math.h>
/*データ構造の定義.....*/
/*各プロセスを実装した関数.....*/
/*メイン関数で各プロセスを連結*/
int main(int argc,char *argv[])
{
seisekiHyou table;
double heikinten;
double hyoujyunhensa;
if(argc<2){
printf("成績表や報告書のファイル名が不明です");
return 3;
}
readSeiseki(argv[1],&table);
heikinten=calcHeikinten(&table);
hyoujyunhensa=calcHyoujyunhensa(&table,heikinten);
calcHensachi(&table,heikinten,hyoujyunhensa);
writeHoukokusho(argv[2],&table,heikinten,hyoujyunhensa);
return 0;
}
ソースファイルseisekishori.c
テスト用の採点表ファイルa.txt
ソースファイルをコンパイルしたseisekishori.exeを次のようなコマンドラインで実行します
>seisekishori a.txt b.txt
構造化手法は非常に有効な手法だ。しかし、より大規模なプログラムを作るためには問題もある。
※オブジェクト指向プログラミングはこの様な問題に有効な手法です