(1.Cプログラムの基礎
今回からいよいよ、C言語の文法の話になります。世の中には習うより慣れろといった教え方もあると思いますが、皆さんは単にC言語のプログラムが作れるようになるだけではダメなので、文法などちょっと抽象的な言葉も学んでもらうことにします。計算機の前に座って沢山プログラムを作っても、それだけでは学べないモノがあります。
ここで学んでほしいことは以下のとおり
※習うより慣れろにしたくないので、教科書と順番を変えてデータ型から話します。
「C言語にはデータ型や変数が在ります」と結果だけ学んでも、なぜデータ型や変数が在るのかその仕組みや理由を正しく推測することは困難です。逆に、計算機の仕組みが少しでも解れば、データ型や変数がある理由が納得できるのではないでしょうか?
計算機は0/1のビット列を処理する仕掛けです。従って、計算を行うには処理したい数値などのデータをどのようなビット列で表現するか、初めに決めておくことが必要です。
※この表現方法が決まらないと足し算の電子回路を作ることもできません。この決め方で回路の作り易さも大きな影響を受けます。大事なことなのです。
01を組み合わせて作れるパターンの数は、たとえば、1byte(8bit)では28=256通りのパターンとなります
。ここで、素直にビット列を2進数と見なせば0から255までの整数と対応付けることが可能です。
| ビットパターン | 表現する整数 |
| 00000000 | 0 |
| 00000001 | 1 |
| 00000010 | 2 |
| 00000011 | 3 |
| ... | ... |
| 01100100 | 100 |
| ... | ... |
| 11111101 | 253 |
| 11111110 | 254 |
| 11111111 | 255 |
下記の表の様に使うバイト数が増えると表現できる値の範囲も広くなります。
| バイト数 | ビット数 | 値の範囲 |
| 1byte | 8bit | 0〜255 |
| 2byte | 16bit | 0〜65,535 |
| 4byte | 32bit | 0〜4,294,967,295 |
| 8byte | 64bit | 0〜18,446,744,073,709,551,615 |
※C言語のデータ型「符号無し整数」はこのような対応で0以上の整数を記録する。
上の表現法では0以上の整数(符号無整数)しか表わせない。 負の値も表したい場合には、工夫が必要になる。
簡単に思いつく方法として一番上のbitを符号と見なし0なら正の数、1なら負の数としてみよう。この方法で1バイト使ってあらわせる数値の範囲は残り7ビットを絶対値とすれば、7ビットで現せる値は0〜127なので±127の範囲 となる。しかし、この方法では0には00000000と10000000の二つの表現が存在してしまう。さらに、足し算の計算では符号無と符号付きで異なる処理が必要になる。結果として計算機の演算回路が増え、機械語の命令数も増えて複雑になる。
もっとうまい方法に2の補数表示が有る。
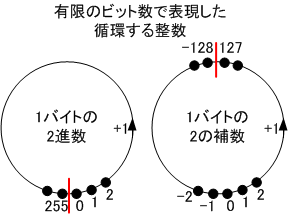
1byteをそのまま2進数と見た場合、現せる最大の数値 は1111 1111で十進の255である。ここで、さらに+1すると、9桁目に桁上がりが起きる。このとき桁上がりした9桁目の1は8桁からあふれている。
2進数8桁の計算回路では、計算結果として8桁分の0000 0000を出力し、9桁目は桁溢れのフラグを1にして示すことにすれば,フラグを無視した結果はは0000 0000で0と同じになる。
2の補数表示では 1111 1111 を-1を表わすビットパターンと見ることにした。2の補数表示では最上位ビットが1の場合は負の数とし、0にするために加える数の分だけ負の値と対応付ける。
下記の表は上から下へ8ビットの加算回路で+1を繰り返した時のパターン変化を示した。 通常の2進数及び2の補数表示と見た場合の8ビットパターンに対応する整数値をみてほしい。
| 8ビットのパターン |
通常の2進数 符号無整数 |
2の補数表示 符号付整数 |
| 1111 1101 | 253 | -3 |
| 1111 1110 | 254 | -2 |
| 1111 1111 | 255 | -1 |
| ここで値が跳ぶ | ||
| (1)0000 0000 | 0 |
0 |
|
0000 0001 |
1 |
1 |
|
|
|
|
|
0111 1111 |
127 |
127 |
| ここで値が跳ぶ | ||
|
1000 0000 |
128 |
-128 |
|
1000 0001 |
129 |
-127 |
|
|
|
|
|
1111 1111 |
255 |
-1 |
| ここで値が跳ぶ | ||
| (1)0000 0000 | 0 |
0 |
|
0000 0001 |
1 |
1 |
ビットパターンを0以上の整数と見ても、2の補数表示の整数と見ても足し算の電子回路は同じものが使えます。すばらしい工夫です。
注意すべきは
1) 同じビットパターンでも符号付きか符号なしかで違う値に対応する事。
※1バイトのビット列11111111は符号付きでは値-1、符号なしでは値255を表す。
2) 符号無整数や2の補数表示は、C言語の整数値の記録方法として使われることが多い。
このため、C言語の整数は+1を続けると値が有限の範囲で循環する。(C言語の処理系依存)
※整数演算で値の範囲を超えるときのオバーフローやアンダーフロー時の動作はC言語の規格としては未定義です。実装依存で異なる場合もありますが、多くの処理系で、エラーを出すことなく循環します。1バイト(8ビット)の符号無しの値255に+1すると0になる。符号付きの値127に+1すると-128になる。このように+1を続けると表す値が循環することになります。
| バイト数 | ビット数 | 0以上の整数とした場合の範囲 | 2の補数表示で 正負の整数とした場合の範囲 |
| 1byte | 8bit | 0〜255 | -128〜127 |
| 2byte | 16bit | 0〜65,535 | -32,768〜32,767 |
| 4byte | 32bit | 0〜4,294,967,295 | -2,147,483,648〜2,147,483,647 |
| 8byte | 64bit | 0〜18,446,744,073,709,551,615 | -9,223,372,036,854,775,808 〜9,223,372,036,854,775,807 |
※
蛇足的メモ: N-M の様な引き算を、N+(-M) の足し算で行えば引き算の回路を作らなくて済む。ここでM から -M を簡単に作れないと無意味だが、2の補数ではMを表すビットパターンを反転してから+1を行うことで -M のビットパターンができる。Mのビットパターンが 01100100(十進数100) ならビット反転は 10011011 となり +1した 10011100(十進数 -100)が -M
ここまでは数値を表わす場合を紹介したが、文字を表わす場合は文字コード表を決めることでビット列と文字を対応させる。
計算機が実用化する以前から通信の分野でモールス符号の様な文字の符号化が行われていた。計算機との関連ではテキストを ビット列として送受信するテレタイプと呼ばれる装置があった。 ビット列と文字を対応させる対応表にはいくつかの種類があるが、そのひとつが7ビットのビット列と文字を対応させたASCIIコード表である。この表には アルファベット、数字、記号の他に文字をタイプする位置を制御する改行(LF)、復帰(CR)などの命令も制御文字として含まれている。ベルを鳴らす制御文字さえある。
| 16進(8bit) | 00 | .. | 0A | .. | 0D | .. | 30 | 31 | 32 | 33 | .. | 40 | 41 | 42 | 43 | .. | 61 | 62 | .. |
| ASCIIコード表 | NULL | LF | CR | 0 | 1 | 2 | 3 | @ | A | B | C | a | b | ||||||
| Cでの文字表記 | \0 | \n | \r | 0 | 1 | 2 | 3 | @ | A | B | C | a | b |
計算機のメモリーはバイト単位なので8ビットで1文字を表現できれば都合がいい。日本でよく使われる8ビットコードはASCIIコードを含む形にして,8ビット目が1の範囲に半角カナを割り当てている。
※8ビットのJISコードはASCIIコードの部分でも若干異なる文字の割り当てがあるので注意
| 文字コード | 00 | .. | 30 | .. | 41 | .. | 5C | .. | 61 | 7F | 80 | .. | B1 | B2 | B3 | .. | FF | |
| ASCII(7bit) | NULL | .. | 0 | .. | A | .. | \ | .. | a | .. | DEL | 7bitを超えた範囲 | ||||||
| JIS(8bit) | NULL | .. | 0 | .. | A | .. | \ | .. | a | .. | DEL | 未定義 | .. | ア | イ | ウ | .. | 未定義 |
現在は漢字のような8ビット以上を必要とする文字に対応する為に16ビットの文字コードが使われる傾向にある。たとえば、日本語版のWindowsパソコンではSJIS(正確にはSJISではなくてWindows-31J)が使われている。さらにUnicodeの様な8,16,32ビットの標準文字コードも作られている。
※C言語の新しい規格C11(2011年)ではUnicode文字列に標準対応
※SJIS ( SiftJIS )
8ビットでは文字を表現しきれない漢字などを16ビットでコード化し、8ビットコードと共存させる為に作られた。
JISコードと共存させる為にJISコードでは文字が割り当てられていない場所(未定義の場所)に漢字など16ビットコードの最初の1バイトを割り当て
、2バイト目も制御コードの値と同じにならないように避けて割り当てている。
文字コード表は非常に種類が多く、互換性も無い場合がある。Unicodeはこれを解決しようとするものだが、問題も多い。日本語の場合も人名をデジタルデータで記録するには外字が必要だったりして簡単ではない。さらに世界中の文字や記号、あるいは古代の象形文字などまでもコード化しようとすると文字コードに関して解決しなければならない問題は多い。
C言語では文字列をメモリー上に連続して並んだ
文字コードで表す。1文字が1バイト使うので、文字列はバイト列になる。文字コードを並べただけでは文字列の終端が判定できないため、終端は
通常の文字とはならないコード値0で示すことに決められている。
たとえば"ABC"はWindows ではメモリー上に16進で 0x41 0x42 0x43 0x00 と4バイトで記憶される。
※0x41はC言語のリテラルで「41」が16進数であることを示す記述方法。(後述のリテラルを参照)
| メモリー番地(16進) | .......... | 0123 | 0124 | 0125 | 0126 | 0127 | 0128 | 0129 | 012A | 012B | ......... |
| 書きこまれた値(16進) | 3F | 40 | 41 | 42 | 43 | 00 | 45 | 46 | 47 | ||
| ASCIIコードでの対応 | ? | @ | A | B | C | NULL | E | F | G | ||
| Cでの文字表記 | ? | @ | A | B | C | \0 | E | F | G |
この方法では文字列の開始番地さえ把握しておけば、文字列の終端はメモリーを読むことで見つけることが可能。
※文字列のビットパターンをどの様にするかはプログラム言語で様々です。文字列の長さが255文字以下で良ければ、最初の1バイトに長さを、続くバイトに文字コードを並べる方法も有ります。パソコン用の初期のBASIC言語でこのような方法が使われていました。この方法では文字列の長さの最大値が制限されますが、文字列の中に0x00のコードを含めることが可能です。文字列をどの様に表すか、これが一番いいといった方法は有りません。
C言語では前記のように文字列を、文字コードが順番に格納されたメモリーの先頭番地で示すことにしました。この番地を記憶するデータが型を、char型の番地の意味で(文字型ポインター)chat*と表記します。
※ポインターについては後期の序論演習IIの中で説明予定です。
ANSIの規格で基本的データに対してはデータ型として表現方法を定めている。ただし、C言語は計算機の性能を最大限に引き出すことも考慮するため、規格には幅があり処理系依存の部分がある。
※処理系依存
プログラムを実行するまでのシステムを言語処理系と言う。C言語のコンパイラ、リンカー、及びリンクされるプログラムのライブラリーなど。計算機のハードウエア、同じ機種でもOS等のソフトウエア環境、言語処理系の提供者などで違いが出ることを「処理系依存」と言う。
|
|
|
|
|
|
char 文字型 |
ビットパターンは256通り。 数と見た場合の符号の 有無は処理系依存です |
1byte |
文字コード表で文字と対応付ける。 漢字などの2バイトコードは入らない |
|
int 整数型 |
符号付き整数、 範囲は処理系依存 |
2-4byte |
2の補数表示が一般的 (Cの規格は2の補数と限定していない) |
|
float ※浮動小数点数型(実数型) |
処理系依存です | 4byte |
有効数字6桁程度 (符号、指数部、仮数部を持つ) |
|
double 倍精度浮動小数点数型 (倍精度実数型) |
処理系依存です | 8byte |
有効数字15桁程度 (仮数部の長さ依存) |
※実数型のビットパターンは2進の浮動小数点数で表現した形になる。実数型と言うよりは浮動小数点数型と呼ぶ方が正確な表現だ。floatは浮動小数点数(floating
point)から来ている。
処理系依存だが、例えばIEEE754では
float 32ビット(符号1bit、指数部8bit(-126〜+127)、仮数部23bit(10進の精度として約6桁))
double 64ビット(符号1bit、指数部11bit(-1022〜+1023)、仮数部52bit(10進の精度として約15桁)
となっている。
※C言語では実数の四則演算は倍精度実数で行われる。float型の値はdouble型に変換してから演算される。私はメモリーを節約したいのでなければ、実数値の格納には通常はdouble型を使うことを勧めます。
C言語では、基本のデータ型の他にさらに幾つかのデータ型を用意している。 これらのデータ型は基本データに修飾子を付けることで示される。
※序論のレベルでは、修飾子を使いこなすことまでは求めません。しかし、一度は読んで、修飾子が在るいことは知っておいて欲しい。
整数型intはデフォルトで正負の数を表現した符号付きである。しかし、unsignedで修飾することで。0以上の整数と対応させる型に変更できる。intが4byteならunsigned intは0〜4,294,967,295の範囲の数を記憶する型になる。
※デフォルト(既定値): 何もしない時に標準的に採用される値・動作などを表す。Wiki
signed intは規定値なのでこの表記は通常は使わず int とのみ記述する、
unsigned intは簡略化して短く unsigned と書くことが許されている。
※char型は1文字のデータを記憶するデータ型だが、1byteの整数と見なして四則演算や代入も可能である。しかし、整数との対応はデフォルト(既定値)でsignedあるいはunsignedの何れとも決められていない。デフォルトの型は処理系に依存する。数値として使う場合はsignedあるいはunsignedを付けてsigned char あるいは unsigned char と明示するのが望ましい。
使うメモリー量を小さく/大きくして表現する値の範囲を変更する修飾子。ただしこの修飾子は必ずしもメモリーの使用量が増減するとは限らず、処理系によっては変化しない場合がある。
|
|
|
|
|
|
short int 短整数型 |
符号付き整数、 | 2byte |
intよりも短い整数。 intと同じ場合もある |
|
int 整数型 |
符号付き整数、 範囲はbyte数依存 |
2-4byte |
2byteの整数では ±3万程度の範囲 4byteの整数では ±20億程度の範囲 |
|
long int 長整数型 |
符号付き整数、 範囲はbyte数依存 |
4-8byte |
intよりも長い整数。 intと同じ場合もある |
| long long int | 符号付き整数 | 8byte | C99から |
|
float 浮動小数点数型 |
処理系依存です | 4byte | 有効数字6桁程度 |
| long float | ANSIでは廃止 | ||
|
double 倍精度 浮動小数点数型 |
処理系依存です | 8byte | 有効数字15桁程度 |
|
long double 拡張精度.... |
doubleと同じか それ以上の精度を持つ |
8byte以上 | doubleと同じ場合も多い |
short intやlong intは簡略化して単にshortあるいはlongと書くことが許されている。
データ型や変数の使うメモリのバイト数はsizeof演算子で知ることができる。
sizeof(型名or変数名);
処理系でデータ型が異なる場合に、データ型や変数が使うメモリーの大きさを教えてくれる便利な演算子である。
#include<stdio.h>
int main(void )
{
printf("sizeof(char)の値は%d\n",(int)sizeof(char));
printf("sizeof(short)の値は%d\n",(int)sizeof(short));
printf("sizeof(int)の値は%d\n",(int)sizeof(int));
printf("sizeof(long)の値は%d\n",(int)sizeof(long));
printf("sizeof(float)の値は%d\n",(int)sizeof(float));
/*
printf("sizeof(long float)の値は%d\n",(int)sizeof(long float));
教科書に書かれた long floatはANSIでは廃止
この為CW5とcygnusでともにシンタックスエラー
*/
printf("sizeof(double)の値は%d\n",(int)sizeof(double));
printf("sizeof(long double)の値は%d\n",(int)sizeof(long double));
return 0;
}
/*実行結果
OS:Windows2000上のCodeWarrior5のC言語環境でコンパイルと実行を行った結果
sizeof(char)の値は1
sizeof(short)の値は2
sizeof(int)の値は4 この環境ではintが4byteなのがわかる
sizeof(long)の値は4 longがintと同じですね。残念
sizeof(float)の値は4
sizeof(double)の値は8
sizeof(long double)の値は8 ここもlong doubleがdoubleと同じ。残念
OS:Windows2000上のGNUのC言語環境(cygnus)でコンパイルと実行を行った結果
sizeof(char)の値は1
sizeof(short)の値は2
sizeof(int)の値は4 この環境ではintが4byteなのがわかる
sizeof(long)の値は4 longがintと同じですね。残念
sizeof(float)の値は4
sizeof(double)の値は8
sizeof(long double)の値は12 long doubleはdoubleより長い。嬉しい?
OS:Windows7上のMicrosoft Visual Studio 11.0 のC言語環境でコンパイルと実行を行った結果
sizeof(char)の値は1
sizeof(short)の値は2
sizeof(int)の値は4
sizeof(long)の値は4
sizeof(float)の値は4
sizeof(double)の値は8
sizeof(long double)の値は8 ここもlong doubleがdoubleと同じ。残念
*/
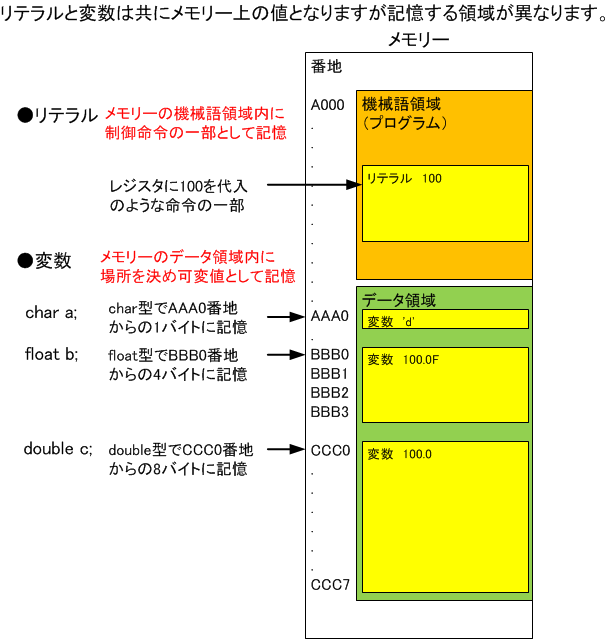
プログラム中にデータの値を直接記述したもの「リテラル:literal」。
※コンパイル時点で値が定まる定数式も定数
として扱う。
例:int a=10+3; などはコンパイル時点で int a=13; に置き換えてから機械語に翻訳される。
計算機内ではデータをメモリー上のビット列で表す。C言語ではデータ型としてデータとビット列の対応が定義されている。リテラルとして表記できるのはデータ型として定義されたものだけです。
整数値をプログラム内に記述するリテラル。しかし、表現できる整数の範囲は限られ上限下限がある。
※上限下限は処理系依存
実数値を固定桁数の2進の小数点数としてプログラム内に記述するリテラル。このため,整数同様に上限下限がある。また精度も有限。
リテラルの表記は10進数で行えるが,10進数では有限桁の少数であっても,2進数では循環小数になるような場合がある。この場合は,できるだけ近い2進数の値とされる。
※ 10進数の0.1は、2進数では循環小数になり有限の桁では正確に表現できない。この結果,C言語の計算プログラムで1.0に0.1を10回足しても2.0に等しくならないといった事が起きる。
C言語の場合 文字とは1バイトのデータです。1文字に2バイト使用する漢字はchar型の定数としては記述できません。
※
'\n'や'\t'は制御文字と呼ばれるもので、印字位置変更を指示するなどの命令コードです。
ASCIIコード表に含まれる制御コードには対応する文字は有りません。そこでリテラルとして表記するためにエスケープシークエンスと呼ばれる形で記述する方法が採用されました。WindowsのCコンパイラで試したところ'\n'は0x0A '\t'は0x09と同じ値でした。しかし他の文字コードを使う計算機では別の値になるかもしれません。
4-1-4で説明したように、文字列は先頭番地で示すことができます。機械語プログラムに翻訳するとき、機械語領域とは別の領域に文字列のビットパターンを作成し、機械語プログラムの中には文字列の先頭番地を書き込みます。この為、文字列定数は機械語プログラムの中ではchar*型のリテラルです。
※char型データの番地を格納する型はchar*と表記する。
HelloWorldを書き出すプログラムにリテラルを用いた記述(太字部分)を追加してみたものです。実行結果がどうなるかを、末尾の実行結果で示しています。
#include<stdio.h>
int main(void)
{
printf("%c %d %f \n", 'A', 10, 3.14);
printf("Hello World\n");
return 0;
}
/*実行結果
A 10 3.140000
Hello World
*/
※リテラルの部分を色々書き換えて実行結果がどう変わるか試してみると良いでしょう。
-------- ここは序論の範囲ではありません。忘れてもいいメモです ---------
定数(変更できない値)をプログラムで実装する方法は幾つかあります。その一つがリテラルです。リテラルは機械語プログラムの中に値が直に書き込まれるので、機械語プログラムを実行中に書き変えない限り変更できません。もう一つの方法は値が変更できない変数として実装し、初期化以外での変数への代入を禁止する方法です。コンパイラが代入文を見つけてエラーを出すようなチェックなら難しくありません。
※C言語ではポインターを使った間接参照が可能です。間接参照による定数の書き換えを防ぐには、コンパイル時だけでなく実行中もメモリーの変更を監視する必要があります。
同じ定数を何度も使うとき、同じリテラルを何度も書くのは大変ですし間違いも起きやすいものです。もし、値を変更することが必要になったら、すべてのリテラルを見つけて書き直すことになるので大変です。
こんな場合に次の例の様に、前処理の文字列の置き換を利用します。
#define PI 3.14159265358979
前処理で文字列「PI」は全て「 3.14159265358979」に置き換えられた後でコンパイルが行われます。桁数の多い数値を何度も書くのは間違いの元なので、いちいちリテラルで数値を示すよりは「PI」を前処理でリテラルに置き換えてもらう方が安全です。値を変更する時も、この1行のみの変更で済みます。
double PI=3.14159265358979;
の様に変数として作ると、間違ってPIに別の値を代入するかもしれない。
const double PI=3.14159265358979;
のようにconstを付けて変数を定義するとコンパイラはPIに値を代入するプログラムをコンパイル・エラーにします。これにより値を変更できない変数を実現できます。
※このようにしても、C言語では間接参照を使って書き換え可能なのが問題。
機械語のプログラミングではデータを読み書きするメモリの番地 と、メモリーに記憶されたビット列がどの様なデータ型なのかをプログラムを書く側が全て把握しておくことが必要だった。これは人間には煩わしい仕事になる。
C言語では変数を定義し、この面倒な仕事をコンパイラに任 せてしまう。
C言語の変数はメモリーの特定番地に変数名を付け、適用するデータ型を定義したもの。変数に使うメモリー番地はプログラムを実行する過程で自動的に決まるので、プログラムを書く側はメモリーの番地を意識する必要はない。プログラマは変数のデータ型と変数名を示すだけでよい。
さらに、コンパイラは変数を用いた計算を 変数のデータ型に応じた機械語に翻訳してくれる。
※変数はデータ型と変数名を指定してブロックの先頭にまとめて定義する方がいい。
C89では初めに定義する決まりになっている。
C99以降は使う前なら定義できるようになった。
人間がプログラムを読む場合でも初めに纏めて書いてある方が解り易い。
注意:変数名は命名規則が在る。また、識別子なので有効な範囲内で名前が重複してはいけない
変数はデータ型と変数名を指定して定義する。
変数は
データ型 変数名;
で定義する
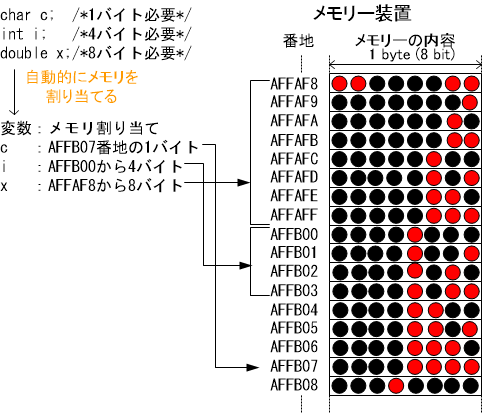
例:
char c;
int i;
double x;
この記述で、コンパイラは各変数へのメモリー割り当てを行います。各データ型ごとに必要なバイト数が異なりますが、重ならないように割り当てます。
※変数のメモリ番地を書き出すプログラム
#include<stdio.h> int main(void) { char c; int i; double x; printf("cのアドレスは %x\n", (unsigned int)&c);/*変数名に&を付けると変数のメモリ番地の値*/ printf("iのアドレスは %x\n", (unsigned int)&i); printf("xのアドレスは %x\n", (unsigned int)&x); return 0; }
※変数と対応するメモリー番地は変数名の前に&を付けて表します。(次回説明)
※メモリを割り当てるときに途中に隙間のある下記の様な割り当てを行う場合もある。(AFFB04 〜06番地が使われていない。)
(注意)教科書では変数を名前の付けられた箱と して説明している。しかし、この例えは、データを箱に出し入れできるボールのようなモノと思い込む原因になる。変数の値を書き換えはできるが、変数に記憶された値をボールのように入れたり出したりは不可能。データは物ではない。 変数はデータを書き留める場所と理解すべきです。初めに算盤を例にメモリーの説明をしました、思い出してください。
データ型 変数名=初期値;
のように定義と同時に初期化もできる。
例: int a=10;
#include<stdio.h>
int main(void)
{
int a=10;
printf("aの値は%d",a);
return 0;
}
/*実行結果
aの値は10
*/
上のメモリーの絵では黒と赤でメモリーの各ビットの値を表してみた。メモリーの値は0/1の様な2値の何れかを取り、中途半端な値は取らない。ここで、変数をメモリーに割り当てても、使う番地を決めただけです。初期化はメモリーの値を書き換えることが必要になり、その処理の分だけ機械語のプログラムが長くなり、処理時間も使う。そこでC言語では、初期化が指定されていない変数は初期化をしない。初期化しなかった変数の値は状況次第で一つに決まらない。この場合に変数の値は不定と言う。
#include<stdio.h>
int main(void)
{
int a;
printf("aの値は%d",a);
return 0;
}
/*コンパイルでは警告
行番号:5: warning C4700: 初期化されていないローカル変数 'a' が使用されます
*/
/*実行結果
aの値は1 <<ここの1は たまたま出た値
*/
※初期値を指定しない場合には0を変数に書き込むプログラム言語も多いが、その分の時間を節約して初期化が不必要な場合には初期化しない選択を許すのがC言語の特徴。
※ここで説明している変数は自動変数です。C言語には静的変数と呼ばれる変数もあり、静的変数は初期化の指定が無い場合は、必ず0で初期化が行われます。これは関数の説明の後で解説します。
{ と } で囲まれた構造のことをブロックという。上のプログラム例の様に、変数の定義はブロックの先頭で行う。定義された変数はそのブロックの内側で有効な変数となる。
C99では使う前であればブロックの先頭以外でも定義可能になったが、解り易いプログラムとするために、皆さんはブロックの先頭でのみ変数を定義してもらいたい。
※ブロックは入れ子にすることも可能。この場合、内側のブロックで、そのブロック内でのみ有効な変数の定義が可能。
翻訳時点で変数名がきちんと解釈されるためには、名前の重複などがあつては困る。長すぎる名前も扱いにくい。そこで名前の付け方にはルールがある。
唯一に識別するための名前。 変数名、関数名などは識別子の条件を満たすことが必要。
※変数には有効範囲(スコープ)がある。同じ有効範囲で同じ名前の変数は定義できない。有効範囲が重ならなければ同じ名前の変数を定義できる。さらに有効範囲が入れ子になっているときは内側の有効範囲で外側と同じ名前の変数を定義できる。変数の名前が重なる場合は,内側の変数の方が有効となる。
代入演算子「=」を使って記述する。コンパイラはデータ型を見て適切な値か確認したうえで、変数のデータ型に従ってメモリーに対応するビット列を書き込む機械語に翻訳する。
int main(void)
{
int a;
int b;
a=10;/*整数10を整数型の変数aに書き込む*/
b=10.0;/*10.0は実数型の値なので整数型の変数に書きこむのは問題あり*/
return 0;
}
/*コンパイル結果 翻訳の時点で次のように警告される
行番号:6 : warning C4244: '=' : 'double' から 'int' への変換です。データが失われる可能性があります。
*/
次の例のように値が要求される場所に変数名を記述すると、変数名はその変数の値の意味になる。
int main(void)
{
int a;
int b;
int c;
a=10;
b=a;/*aの値をbに書き込む*/
c=a+b; /*変数aとbの値を足し算してcに書き込む*/
return 0;
}
C言語では「=」の記号は左辺の変数に右辺の値を代入する命令である。ここで右辺には必ず何らかの値が来るはずなので、b=a;では変数aの値を読みだして、その値をbに書き込む。c=a+b;の記述では「+」が左右の値を足し算した値を求める命令なので変数a,bの値を読みだして足し算を行い変数cに書き込む。
上の説明は理解できただろうか? 確認するために次の記述a=a+10;で変数aの値はどうなるか考えてみよう。
#include<stdio.h>
int main(void)
{
int a=10;
a=a+10;
printf("aの値は%d",a);
return 0;
}
変数の値が必要な場所ではコンパイラは変数の値を読みだす機械語を生成する。読みだされた値は変数とは別の場所に一時的に記憶して足し算などの演算に使われる。上のプログラムでは変数aから10を読みだして演算を行い、結果の値20を変数aに書き戻す。従ってaの値は20に成る。
※演算のための一時的記憶場所は、変数とは別に用意されている。
計算機の仕組みで紹介した機械語のプログラムではメモリーからレジスタにデータを読みだしてから演算を行いをレジスタに出力した。その後でレジスタの値をメモリーに書き戻したことを思い出してほしい。
リテラルの例題プログラムを変数を用いた記述(太字部分)に書き換えた例です。
#include<stdio.h>
int main(void)
{
char a='A';
int b=10;
double c=3.14;
/* 文字列はその先頭番地をchar*型の変数に記憶できる。 */
char* d="%c %d %f \n";
char* e="Hello World\n";
printf( d, a, b, c);
printf (e );
return 0;
}
/*実行結果
A 10 3.140000
Hello World
*/
Cのプログラムではメモリーをプログラムの制御命令を記憶する機械語領域と計算対象の値を記憶するデータ領域の2つの領域に分けて使います。変数はデータ領域に値を記憶しますが、リテラルは機械語領域に制御命令の一部として値を記憶します(XXレジスタに100を代入のような命令)。
レポートツールの説明に在った課題1は今後の課題提出に必須です。もしまだ送信していなければ最優先で課題1を完了してください。
タイピングの練習を兼ねて、C言語のデータ型などのつづりを覚えてもらいます。初期ファイルをダウンロードして下記の原本を写経してください。※コメント部分は写経不要
実行できないファイルはレポートとして送れません。 ツール左のウインドウからエラーの項目を開いて個々に確認できますし、エディターの画面ではエラーの出た行に赤いマークが警告のある行に黄色いマークが出ます。間違い探しの参考にしてください。エラーはソースファイルの上の行から消していきましょう。何度もコンパイルしなおしてエラーを減らしていきます。どうしても分からないエラーが出るようなら練習にもなるので、書き直すことを推奨します。
※下のソースコードをコピペしたソースファイルが実行可能なことは確認済です。
※教えていないprintfの使い方をしています。printfについては次回詳しく説明します。
/*注意 コメントは間違いのもとになるので写経から省くこと 字下げは重要なので必ず行うこと。(行の書き出し位置は手本のように下げること) IEで見ると手本の字下げが正しく表示されないことがあります。Firefoxで見てください */ #include<stdio.h> int main(void) { /* 字下げ { }の内側は行の先頭に空白を4文字入れてください。 1234 */ /*基本データ型の変数を用意*/ char c='A'; int i=1023456789;/*10億... 桁数を間違えないように注意*/ float f; double d=3.1415926535; /*変数が使うバイト数を調べる*/ printf("size\n"); printf("c %d \n", sizeof(c)); printf("i %d \n", sizeof(i)); printf("f %d \n", sizeof(f)); printf("d %d \n", sizeof(d)); printf("\n"); /*----文字型変数----*/ printf("c %c \n", c);/*文字として表示*/ printf("c %d \n", c);/*10進数として表示*/ /*cに+128を繰り返してみる*/ /*c+128の計算は整数の足し算だが これはint型の足し算として行われる。*/ /*計算結果がint型なのでchar型の値にするために(char)(c+128)としている*/ printf("c+128 %d \n", (char)(c + 128)); printf("c+256 %d \n", (char)(c + 256)); printf("c+384 %d \n", (char)(c + 384)); printf("\n"); /*----整数型変数----*/ printf("1*i %+11d \n",i);/* %+11d は符号を付けて11ケタの10進数表示 */ /*2倍3倍と繰り返してみる*/ printf("2*i %+11d \n", 2 * i); printf("3*i %+11d \n", 3 * i); printf("4*i %+11d \n", 4 * i); printf("\n"); /*-----実数型変数----*/ f=(float)d; /*値を倍精度から単精度に変換して代入*/ printf("f %12.10f \n", f);/*有効数字が落ちているかな?*/ printf("d %12.10f \n", d); return 0; }
実行結果は以下のようになります。
size c 1 i 4 f 4 d 8 c A c 65 c+128 -63 c+256 65 c+384 -63 1*i +1023456789 2*i +2046913578 3*i -1224596929 4*i -201140140 f 3.1415927410 d 3.1415926535
●コンパイルエラーになる例
セミコロン「;」が抜けている。
=+などの記号で倍角の文字=+を使っている。
●実行時エラー(想定した動作をしない、あるいは暴走など)になる例
printfの書式指定子 %d を %S や %n と書き間違えている。
この下は序論の範囲では必要な時に思い出してくれれば良い。
しかし、構造体を使うときはtypedefをよく使うので思いだすこと。
データ型の別名を定義可能になっている。この機能で修飾子の付いた長い型名も簡潔な型名にできる。
typedef データ型 新しいデータ型の名前;
例 typedef unsigned long int LINT;
LINT a=123456789L;
次の列挙型などの場合、型名が長くなるのでこの様な別名定義が頻繁に使われる。
enumeration
数個の限られた整数値を取るデータに対しては、数値に順番に名前付けしたデータ型を宣言できる。
enum タグ名{ 列挙定数, 列挙定数[=整数定数式], [ ]の部分は省略可能な部分で列挙定数の値を指定する場合に使う ....列挙定数の並び... };
ここで変数を宣言する場合のデータ型に対応する部分は「enum タグ名」である。教科書23pの様にtypedefと組み合わせるとデータ型の名を簡略な新しい名前にできる。
列挙定数は識別子(名前の重複は許されない)である。従ってプログラム中でそのまま定数として使える。
列挙定数の値は順番に書かれた順に1づつ増加する。しかし、値を指定することも可能。最初の定数値は指定されていない場合は0となる。
プログラム例:列挙型は多くの場合、整数値に別名を付けるのに用いられる。たとえば、下記のような月や曜日のデータ表現を整数値に割り当てたプログラムでは適切な別名で値を表現できるとプログラムが分かり易く書ける。
#include<stdio.h>
/*列挙体宣言:enum タグ名{ 列挙定数,...};*/
enum month{
JANUARY=1,FEBRUARY =2,MARCH=3,
APRIL=4,MAY=5,JUNE=6,
JULY=7,AUGUST=8,SEPTEMBER=9,
OCTOBER=10,NOVEMBER=11,DECEMBER=12,
UNDECIMBER=13 /*太陰暦で使用*/
};
/*変数のデータ型名として使いたければtypedefが便利*/
/*但し実際のデータ型はintである*/
typedef enum { /*enumのタグ名は省略可能*/
MONDAY=0,TUESDAY=1,WEDNESDAY=2,
THURSDAY=3,FRIDAY=4,SATURDAY=5,
SUNDAY=6
}WEEKDAY;
/*列挙定数を数値の別名として使うだけならこんな書き方も可能*/
enum {NO_ERROR=0,ERROR};
char *weekday[7]={
"Monday","Tuesday","Wednesday",
"Thursday","Friday","Saturday",
"Sunday"
};
int main(void){
WEEKDAY i;/*実際はint iと同じ*/
for(i=MONDAY;i<=SUNDAY;i++){
printf("%s\n",weekday[i]);
}
return NO_ERROR;
}
配列 ポインター 構造体、共用体 これらについての説明は後で出てきます