(0.1�@�b����̗���)
���߂Ƀv���O���������s����v�Z�@�̎d�g�݂�C����̗l�ȃv���O���~���O���ꂪ�K�v�Ƃ���闝�R����b�������Ǝv���܂��B �����Ŋw��C����͌v�Z�@�̃n�[�h�E�G�A�Ɉˑ����镔���܂ōׂ�������ł��錾��Ƃ��č���Ă��邽�߁A ���̃v���O��������ɔ�v�Z�@�̎d�g�݂��������f����Ă��邩��ł��B �������A�v�Z�@�̎d�g�݂ɂ��Ă͓������ɊJ�u�����u��̃V�X�e���H�w��b�v�ł�����Ɛ�������܂��B�����͈�ǂ�����x�ł��܂��܂���B
�����ŗ������Ăق����̂�
�v�Z�@�͋L���A���Z�A�����3���s���@�B�B�i���ۂ́A���̑��ɊO���Ƃ̓��o�͂��K�v�j
�����F�@��L�̂悤�Ȍv�Z�@�ł́A�v���O�����i�v�Z�菇�j�̓Ǐo�����x�����Z���x�Ɠ������x�ɂ͑������Ƃ����߂��܂��B �Ⴆ�v���O���������̊J���������i�p���`�J�[�h�j�⎆�e�[�v����ǂݍ���ł���ƁA1�b�Ԃ�1000�̐��䖽�߂�ǂݏo���̂��e�Ղł͂���܂���B����ŁA���݂̌v�Z�@�̉��Z���x��1�b�Ԃ�3�O������x�ł��B
�^��ǂ�p�����ŏ��̓d�q�v�Z�@�ł���ENIAC��1�b�Ԃ�5000��̉����Z���ł��܂����B�p���`�J�[�h����v���O������ǂ�ł��ẮA�v�Z���x���x���Ȃ��Ă��܂��܂��B������ENIAC�ł͉��Z���u���p�ӂ��ĖړI�̌v�Z���s����悤�ɉ��Z��H�̓��o�͂��q���܂����B�v�Z������e�̕ύX�͉��Z���u�̐ݒ�ύX�Ƃ����̌����̕ύX�ōs���܂����B
ENIAC�͖C�e�̒e���v�Z�Ƃ���������̖ړI�̌v�Z���s����p�v�Z�@�Ƃ��Ă͗D�ꂽ���̂ł��B�������A���̌v�Z�ɂ��g�����Ƃ���ƁA�v���O�����̕ύX�͐ݒ�X�C�b�`�̕ύX�ƌ����̕ύX�ōs�����߁A��ώ�Ԃ̂������Ƃł����B
�����ŁAENIAC�̎��̐���̌v�Z�@�ł́@������e�ʂ̋L�����u��p�ӂ��A�v�Z����f�[�^�����łȂ��v���O�������L������悤�ɂ����v���O���������^�v�Z�@���嗬�ƂȂ�܂����B
�v���O���������^�v�Z�@�F
�@�L�����u�̃f�[�^�����o����1�̔ėp���Z��H�ɑ���A���̉��Z���ʂ��L�����u�ɏ������ށB�����ŁA���Z�Ώۂ̃f�[�^�Ɖ��Z�̎�ނ��v���O�����Ő��䂷��Ηl�X�Ȍv�Z���s�����Ƃ��\�ƂȂ�B�v���O�������̂��f�[�^�Ɠ����L�����u�ɋL�����邱�ƂŁA�v���O�����̕ύX���e�ՂɂȂ�B�ėp����������R�X�g�B
�@�������A�v�Z���x�Ɍ����������Ńv���O������ǂݏo���鍂����e�ʂ̋L�����u�i�������[�j���s���B
���v���O���������^�v�Z�@���m�C�}���^�v�Z�@�Ƃ��Ă�܂��B�v���O���������^�v�Z�@�̎d�g�݂��L�߂������m�C�}���̖��O�ŏ�����Ă������Ƃɂ��B
���v���O���������^�v�Z�@�͋L�����u�̃f�[�^��1�Âǂݏ������A���Z��1�̉��Z���u��1�Â��ԂɎ��s����̂ŁA��{�I����x�Ɉ�̂��Ƃ������s���Ȃ��B�����̉��Z���u���q���Œ��ڃf�[�^������������ɉ��Z����f�[�^�t���[�^�v�Z�@�ɔ�ׂāA�v���O���������^���v�Z���x���̂����_�ł��B
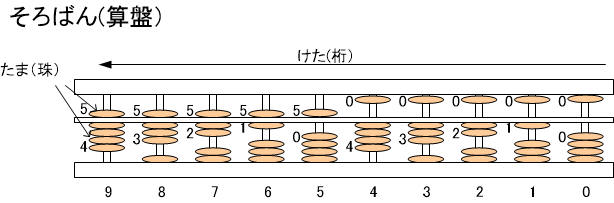
���͂قƂ�nj���@�������������܂��A�Z���i�����j�ƌĂ��v�Z�Ɏg���������܂��B�Z�Ղ͐��l�f�[�^����i���܁j�̈ʒu�ŕ\���A�e�Ղɏ��������邱�Ƃ̂ł���L�����u�Ƃ����܂��B�M�Z���s���Ƃ��̎��Ɖ��M�Ə����S���ɑ���������̂ł��B
���ɂ���S�̎���P�Âグ�čs�����Ƃ�1+1+1+1=4�̂悤�ɉ��Z���ł��܂��B�Z�ՂōH�v����Ă���̂�5��\����̎�ł��B4+1=5�ƂȂ����Ƃ��́A��̎�������āA���̎�4��S�ĉ���5��\���܂��B1�̌���0�`9�܂ł�10��ނ̃p�^�[��������̂ŁA�\�i�@��1�P�^���̃f�[�^���Z�Ղ̂P���ɋL���ł��܂��B
�����̂悤�ɂP����0�`9�܂ł̉��Z�⌸�Z�Ȃǂ��ł���̂ł����A�����ł͋L�����u�ƍl���Ă����܂��B
�@�v�Z�@�̏ꍇ�̓f�[�^��0/1�̗l��2�̏�Ԃ̂ǂ��炩�ŕ\���̂ŁA�����Z�Ղ��g���Čv�Z�@�̋L�����u�i�������[�j�����Ƃ����牺�̂悤�ɂȂ�ł��傤�B�@���̎Z�Ղł͈�ԉ�����1,2,4,8,16,32,64,128��\���W�̎�łP���ɂȂ��Ă��܂��B�P���łȂ��0�`255��256��ނ̃p�^�[�������܂��B
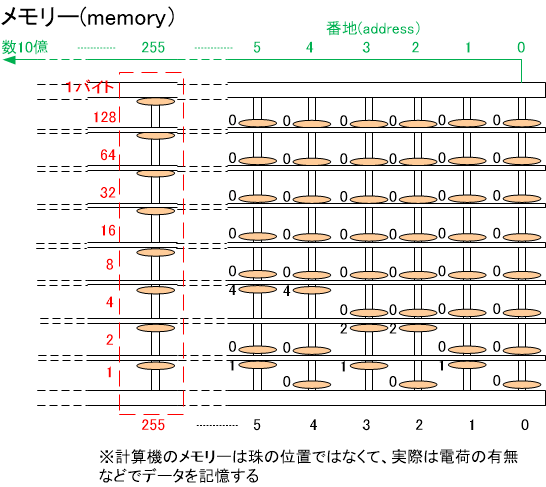
�@YES/NO��0/1�Ȃ�2�̏�Ԃ̓��ǂ��炩���������ʂ�1bit�ƌ����܂��B
�v�Z�@�̋L�����u�ł�8bit��1�̓Z��Ƃ��āA1byte�ƌĂԂ̂��ʗ�ł��B�i8bit��1byte�j
��̃������[�̐}�ł́A1�̎�̈ʒu��1bit�A�@8�̎삪����1����1byte�@�̏����L�����܂��B
�L���ꏊ�͎Z�Ղ̌��ɑ��������Ԓn�iaddress�j�ŋ�ʂ��܂��B���̔Ԓn�͏�̐}�̂悤��1byte���ɐU��̂��ʗ�ł��B�L�����u���Ԓn�i�A�h���X�j�͖c��Ȑ��ɂȂ�A4GB�i�M�K�o�C�g�j�� �L�����u�����v�Z�@�̏ꍇ��40�����x�̐��ɂȂ�܂��B
��������G�i�M�K�j�͖{����109�ł����A230�̈Ӗ��Ŏg�����Ƃ��݂�܂��B210=1024�łق�1000�ł��邱�Ƃ���230���قڂP�O���ɂȂ邩��ł��B
���M�K(G)�͖{����109���Ӗ���230�ł͂���܂���B������230���M�r�iGi�j�Ƌ�ʂ��ČĂԂ��Ƃ���������Ă��܂��B����ɏ]���͂SGB�ł͂Ȃ��ĂSGiB�ƕ\�L���邱�ƂɂȂ�܂��BWiki���Q��
��̃������[�����ɓ|���āA�L�����u�̏�Ԃ��ȒP�ȊG�ɂ���ƈȉ��̂悤�ɏ�����ł��傤�B���Ԃɕ��Ԓn���ƂɁ@8�̂O/1���L�����Ă��܂��B(�삪��̂Ƃ���1�A���̎���0�Ƃ���8�̎�̏�Ԃ�8��01�̕��тŎ����Ă��܂�)
| �Ԓn | �l |
| 0 | 00000000 |
| 1 | 00000001 |
| 2 | 00000010 |
| 3 | 00000011 |
| 4 | 00000100 |
| 5 | 00000101 |
| ........... | .......... |
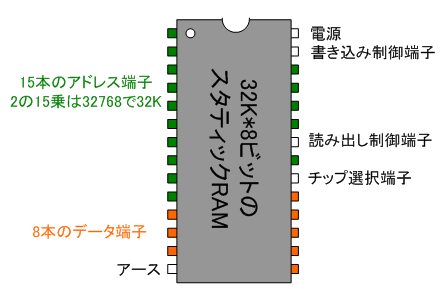
���ۂ̋L�����u�́A���LIC�`�b�v�̖͎��}�Ɏ����l�ɁA�ǂݏ������w�����鐧��[�q�A�Ԓn���w�����镡���̃A�h���X�[�q�A�f�[�^ ����o�͂��镡���̃f�[�^�[�q�����Ă���B
�A�h���X�[�q
�d��ON/OFF�̑g�ݍ��킹�ŔԒn������
�B2�{�̒[�q���������ON/OFF�̑g�ݍ��킹��4�ʂ�A4�{�̒[�q���������ON/OFF�̑g�ݍ��킹��4�~4��16�ʂ�ɂȂ�B8�{��16�~16��256�ʂ�B16�{��256�~256�ʂ�A32�{�ł� 232�i=��40���j�ʂ�ƁA�A�h���X���w�肷�邽�߂̐��͌����I�Ȑ��ł����B
�f�[�^�[�q
�d��ON/OFF�̑g�ݍ��킹�ŏ������݂�ǂݏo���̃f�[�^�������B�ǂݏ����œ��������g���B
����[�q
�d����ON/OFF�ő��u�̑I���A�I�����ꂽ�Ƃ��̏������݂�ǂݏo���Ƃ��������샂�[�h�̎w����s���B�@
�@
�����̐l��10�i���Ŏl�����Z�i�a���Ϗ��j���s���܂��B�����Z�͎n�߂͎w��܂�Ȃ��琔���܂����A�o�����ނ�1���̑����Z���炢�͊o���Ă��܂��̂ŁA��͂�������x���g�ݍ��킹�Č��̑������̑����Z���ł���悤�ɂȂ�܂��B�����Z�����l�ł����A�|���Z�̌v�Z�͋����L������Α����Z�Ƒg�ݍ��킹�Čv�Z�ł��܂��B����Z�����̊|���Z�����g���Čv�Z���܂��ˁB���͒m��Ȃ��̂ł����A�͎̂Z�Ղ̎d�g�݂ɍ��킹������Z�̋�����g���Ă��������ł��B
���i�g���P�O�i���͂P�O�̐����i�����F�O�A�P�A�Q�A�R�A�S�A�T�A�U�A�V�A�W�A�X�j�ƈʎ��ɂ���Đ��l��\�킷���@�ł��B2�i���͎g��������2�œ����悤�Ɉʎ����g�����l�\���@�ł��B �����̏ꍇ�A�����ɂ͕����O�A�P���g���܂��B
�Q�i���iTwo binary numbers�j�̎l�����Z�̃��[����10�i���ɔ�ׂĂƂĂ��ȒP�ł��B������v�Z�@��0/1�̗l��bit�P�ʂ̃f�[�^�\�����g���v�Z���s���܂��B�����Z��0+0=0, 0+1=1, 1+0=1, 1+1=10 ��4��ނ��A�|���Z��0*0=0, 0*1=0, 1*0=0, 1*1=1 ��4��ނ���ʂł���Ό����I�ɂ͏\���ł��B
�����ۂɂ�8���A16���A32���A64����2�i���̎l�����Z��H����邽�����グ�̎d�g�����K�v�ł��B
���v�Z�@�̉��Z���u�͎l�����Z�����łȂ���X�̘_�����Z�̉�H���p�ӂ��Ă��܂��B
���l�Ԃ��v�Z�@���g�����߂ɂ́A�l�Ԃɉ���Ղ�10�i���ƌv�Z�@�ɍD�s����2�i���̕ϊ����K�v�ł��B���̕ϊ��͐l�ԂƂ̃f�[�^���o�͂ŕK�v�ɂȂ邾���Ȃ̂ŁA�S�̂̌v�Z���Ԃɔ�ׂ�����ꕔ�ɂȂ�܂��B�v�Z�@�̍��Ղ��̕����D�悳��܂����BENIAC�ƌĂ��ŏ��̎��p�I�ȓd�q�v�Z�@��10�i�@�Ōv�Z���Ă��܂������A�Ȍ�̌v�Z�@��2�i�@���g���Čv�Z���Ă��܂��B
�ȉ��ɁA2�i���̉��Z���@�B�ł��ł���قNJȒP���Ƃ������Ƃ�̌����Ă��炤���߂ɁA����p�ӂ��܂����B
2�̔{����1,2,4,8,16,32,64,128�A�A�A�ł�����100�͎��̕\�̂悤��64�̌���32�̌���4�̌���1��2�i���ŕ\���܂��B
| �� | 64 | 32 | 16 | 08 | 04 | 02 | 01 |
| �l | 1 | 1 | 0 | 0 | 1 | 0 | 0 |
100��64+32+4�Ȃ̂�1100100�ł��B
50��32+16+2�Ȃ̂�110010�ł��B ��50��100�̔����Ȃ̂ŁA01�̕��т�1�����ւ���܂��B
�ȉ���Javascript�̃t�H�[����10�i���Ƃ̑Ή����m�F���Ă݂܂��傤
������2�ɂȂ�ƌ��グ�������邱�Ƃ�Y��Ȃ����10�i�̑����Z�Ɠ��l�ł��B
������10010110 10�i����128+16+4+2��150�ƈ�v���܂��B
�|���Z�ł����A����������ł��B�~110010�Ȃ̂�1������3��������1100100���P�^�����炵�ē]�L���A����3�s�𑫂��Z�����OK�ł��B���̂悤�Ȃ��͕̂K�v�͂���܂���B
������10010110 10�i����4096+512+256+128+8��5000�œ�����10�i�̌v�Z�ƈ�v���Ă��܂��B
| �� | 4096 | 2048 | 1024 | 0512 | 0256 | 0128 | 0064 | 0032 | 0016 | 0008 | 0004 | 0002 | 0001 |
| �l | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
����̌v�Z�t�H�[���͒��i��3�s�����Ȃ��̂Ŋ|���鐔�ɂP��3�ȏ゠��Ǝg���܂���B�蔲���ł�^^�B
������2�i���͌����������Č���̂ŁA�v�Z�@�̐��E�ł�2�i��4�������܂Ƃ߂�1���ŕ\�����P�U�i�� (Hexadecimal number)��2�i����\�L����̂��ʏ�ł��B�����ɂ͕���0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F��16�������g���܂��B
| 2�i�� | 0000 | 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 | 1000 | 1001 | 1010 | 1011 | 1100 | 1101 | 1110 | 1111 |
| 16�i�� | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
| 10�i�� | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
�������[�̒P�ʂƂ��Ďg����o�C�g��2�i��8�����Ȃ̂ŁA16�i����2���ł��ꂢ�ɕ\���ł��܂��B���ׁ̈A�P�o�C�g���̃f�[�^�����L�̂悤��16�i��2���ŕ\�킷���Ƃ��ǂ��s���܂��B�i10�i���ł�0-255�ɑΉ��j
00, 01,�D�D�D0F, 10,�D�D�DFE, FF
���W�X�^�iregister�j�͉��Z���u�̓��o�͒l��ݒ肷�鍂���̋L�����u�ŁA���Z��H�ƈ�̉����Ă��܂��B���W�X�^�͕�������A,B,C..���̖��O��������ŋ�ʂ���܂��B
�v�Z�@�́A�܂��L�����u�����U���W�X�^�ɒl���R�s�[���܂��B���ɁA���̃��W�X�^�̒l����͂Ƃ��ĉ��Z���s�����ʂ����W�X�^�ɏ����܂��B���̌�ŕK�v�Ȃ烌�W�X�^�̒l���L�����u�ɏ����o���܂��B�ł��邾���f�[�^�����W�X�^�ɒu���ĉ��Z��i�߂�����A�������[�ƃf�[�^��ǂݏ������鎞�Ԃ��Ȃ��č����ȏ������\�ł��B
�����݂̌v�Z�@�̓������[�̓ǂݏ������Ԃ����Z���u�̉��Z���Ԃɔ�ׂ�1���ȏ�x�������肷��B���W�X�^�͐������Ȃ��̂ő����̃f�[�^���L���ł��Ȃ��B�������A�\�Ȃ烌�W�X�^���g���Čv�Z�������ߍŌ�̌��ʂ������������[�ɏ������ޕ����������f�R�����B
���̖͎��}�̗l�ɉ��Z�̎�ނƉ��Z���͂ɂȂ��郌�W�X�^�̑I���ő��l�ȉ��Z���ł��܂��B���Z���ʂ�A���W�X�^ �i�A�L�������[�^�j�ɏ������܂�܂��B���̎��A�����Ƀt���O���W�X�^�ɉ��Z���ʂ��A�[���A�}�C�i�X�A�����Ȃǂ�����1bit�̏�������܂Ƃ߂����̂��������܂�܂��B�ebit�����������Ă��� ���Q�Ă��邩�Ɍ����Ăăt���O(flag)�ƌ����܂��B�[���t���O�������Ă���A���O�̉��Z���ʂ��[���ł��邱�Ƃ������܂��B
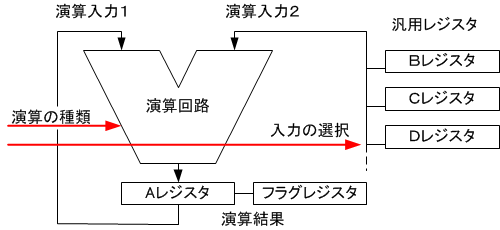
�����̖͎��}�ł�A���W�X�^�����Z�̈���̓��͂ɏ�Ɍq�����Ă���B���̗l�Ȑv�ɂ��邱�ƂŐ����H�̎d���̎�ނ����Ȃ����A���Z���u��P�������邱�Ƃ��ł��܂��B���݂̉��Z���u�������Ȃ��Ă���Ƃ������Ƃł͂���܂���B�F�X�Ȃ��̂��݂�̂ł��B
��Wiki�ȂǂŐF�X���ׂĂ݂悤�O�O
�ݎZ��iAccumulator�j�A���W�X�^�A���Ԏ��v�Z�@
- Wikipedia�AComputer History Museum�@��
�K���@��
(differrence engine)
�d��̃{�^����
�P�A�Q�A�{�A�R�A�S�A��
�Ɖ�����46�ƕ\������12+34�̑����Z���ł��܂��B�����ŁA�d��̃{�^�����������Ԃ����������̂��v���O�����ƌĂԂ��Ƃɂ��܂��傤�B�v���O���������ď����ꂽ���Ԃǂ���Ƀ{�^�������������@�B�����ΐl����������Ɍv�Z�ł��܂��B���̂悤�Ƀv���O������ǂ�ʼn��Z�ƋL���𐧌䂷��̂����䑕�u�ł��B
���v�̌v�Z���s���ꍇ���l���Ă݂܂��傤�B�L�����u���琔�l�����Ԃɓǂݏo���đ����Z������v�����߂��܂��B�f�[�^��00001100�Ԓn��00001101�Ԓn�̃������[�ɂ���̂Ȃ�A
�@�L�����u��00001100�Ԓn�̃f�[�^�̏o�͂��w�����A���Z���u�ɏo�͂�A���W�X�^�ɋL������悤�Ɏw���B
�A���Z���u��A���W�X�^�̒l��B���W�X�^�ɃR�s�[
�B�L�����u��00001101�Ԓn�̃f�[�^�̏o�͂��w�����A���Z���u�ɏo�͂�A���W�X�^�ɋL������悤�Ɏw���B
�C���Z���u��A+B���v�Z����A�ɏ������݂��w���B
�D���Z���u��A���W�X�^�̃f�[�^�̏o�͂��w�����A�L�����u�ɏo�͂�00001110�Ԓn�ɋL������悤�Ɏw���B
�E��~
...�ƘA�����Ďw�����o�����ƂŃ������[��00001110�Ԓn�ɍ��v�����߂��܂�
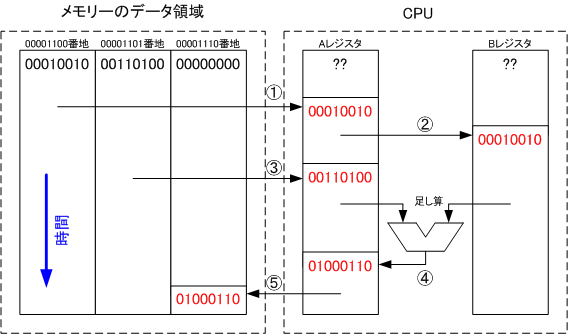
���̂悤�ɁA�L���Ɖ��Z�̉�H�ɓK�ȏ��ԂŎw�����o���Ηl�X�Ȃ��Ƃ��\�ɂȂ�܂��B���̈�A�̎w�����o���̂������H�̖�ڂł��B
���@�A�̗l��2�x��Ԃ�������00001100�Ԓn�̃f�[�^��B���W�X�^�ɃR�s�[����ƊF�Ȃ���͎v���ł��傤�B�������A���̌Â��v�Z�@�ł͒���B���W�X�^�ɂ��R�s�[�ł���悤�ȓd�q��H�ɂ͂��Ȃ������̂ł��B����́A���߂��H�̋K�͂͏������A�v�Z�͑����Ɨl�X�ȗv���Ŏ�̑I�����s�����A1�̌��ʂł��B�S�Ă̌v�Z�@�������Ȃ��Ă����ł͂���܂���B
�v���O�������������ł́A���ꂼ��̐���ɑΉ�����r�b�g�p�^�[���i���߃R�[�h�j�����߂Ă����܂��B���̊e����ɑΉ��������߃R�[�h���@�B��(machine language)�ƌĂт܂��B�i�@�B��͌v�Z�@�̋@��ŗl�X�� ���j
�L�����u�̃A�h���X���ɁA����菇�ǂ���ɋ@�B�����ׂ����̂��v���O�����ɂȂ�܂��B
�ǂ̃A�h���X���疽�߃R�[�h��ǂނ��L�����Ă����v���O�����J�E���^�ƌĂ���p���W�X�^������܂��B���䑕�u�̓v���O�����J�E���^�Ŏ����ꂽ�������[���疽�߃R�[�h��ǂ�őΉ����鐧����s���A�����Ƀv���O�����J�E���^�l��ǂ��������₷������J��Ԃ��܂��B���̌��ʁA���䑕�u�͋L�����u�̃A�h���X�� �ɖ��߃R�[�h�����ԂɎ��s���邱�ƂɂȂ�A�v���O���������s����܂��B
�Ⴆ�L�����u��X�Ԓn����A���W�X�^�Ƀf�[�^���R�s�[���閽�߃R�[�h��00111010��X�̔Ԓn�͑���2�o�C�g�Ŏ����BA+B���v�Z��A�ɓ���閽�߃R�[�h��10000000�B�Ƃ�������ɋ@�B�ꂪ���߂��Ă���Ƃ��܂��傤�B���L�̂悤�ɁA���߃R�[�h�ƃf�[�^���L�����u�Ɋi�[���A�v���O�����J�E���^��0�Ԓn�ɐݒ肵�Ă�����s�J�n������v�̌v�Z���s���܂��B���̕\�̓������[�̔Ԓn�Ə������܂ꂽ�l�A���̒l�̉������ׂ����̂ł��B
| �Ԓn(���_����) | �l(2�i) | ��� | ���߃R�[�h/�f�[�^ |
| 00000000_00000000 | 00111010 | �������̒l���`���W�X�^�ɃR�s�[ | ���߃R�[�h |
| 00000000_00000001 | 00001100 | �f�[�^1�̃������Ԓn����1�o�C�g | ���߃R�[�h |
| 00000000_00000010 | 00000000 | �f�[�^1�̃������Ԓn���1�o�C�g | ���߃R�[�h |
| 00000000_00000011 | 00100111 | �`���W�X�^�̒l���a���W�X�^�ɃR�s�[ | ���߃R�[�h |
| 00000000_00000100 | 00111010 | �������̒l���`���W�X�^�ɃR�s�[ | ���߃R�[�h |
| 00000000_00000101 | 00001101 | �f�[�^2�̃������Ԓn����1�o�C�g | ���߃R�[�h |
| 00000000_00000110 | 00000000 | �f�[�^2�̃������Ԓn���1�o�C�g | ���߃R�[�h |
| 00000000_00000111 | 10000000 | �`+�a�����` | ���߃R�[�h |
| 00000000_00001000 | 00110010 | �`���W�X�^�̒l���������ɃR�s�[ | ���߃R�[�h |
| 00000000_00001001 | 00001110 | �������ރ������Ԓn�̉���1�o�C�g | ���߃R�[�h |
| 00000000_00001010 | 00000000 | �������ރ������Ԓn�̏��1�o�C�g | ���߃R�[�h |
| 00000000_00001011 | 01110110 | ���s��~ | ���߃R�[�h |
| 00000000_00001100 | 00010010 | �f�[�^1 | �f�[�^ |
| 00000000_00001101 | 00110100 | �f�[�^�Q | �f�[�^ |
| 00000000_00001110 | 00000000 | ���ʂ��������ޏꏊ | �f�[�^ |
���������[�̒l�����߃R�[�h�Ȃ̂��f�[�^�Ȃ̂��́A�l�ł͋�ʂł��Ȃ��B
���䑕�u�͋@�B��𗝉����Ă���̂ł͂Ȃ��A���߃R�[�h�Ō��߂�ꂽ������s���Ă��邾���ł��B���̓���͋@�B��𗝉����ē����Ă���悤�Ɍ����邩������܂���B
���y����ǂ�ʼn��t���鎩���I���K���Ɠ����悤�ɁA�v�Z�@�̓������[��ɕ���0/1�̃p�^�[����ǂ�œ������u�ł��B
�@�B���2�i���̕��тŐl�ԂɂƂ��Ă̓v���O�����̎�Ԃ���ϔς킵�����̂ł��B1-1-4�̗���ȉ��Ɏ������A���l��2�i����01�ŏ�����Ԃ����炷�ׂɑS ��16�i�ŕ\�L���܂����B���̗��intel��8080�n�̋@�B��ŁA�������[�̔Ԓn0000����1�o�C�g�Â��߃R�[�h��������Ă��܂��B
�����߃R�[�h�͋@��ňقȂ�܂��B�]���āA�����v�Z���s���ꍇ�ł��قȂ�@��̌v�Z�@�̏ꍇ�ɂ͋@�B������������K�v������܂��B
�Ԓn�F�l�i16�i�\�L�j
0000: 3A ;000C �Ԓn�̃������̒l���`���W�X�^�ɃR�s�[(�R�o�C�g�g�����߃R�[�h)
0001: 0C ;..������2�o�C�g���Ԓn000C������
0002: 00 ;..
0003: 47 �@;�`���W�X�^�̒l���a���W�X�^�ɃR�s�[
0004: 3A �@;000D �Ԓn�̃������̒l���`���W�X�^�ɃR�s�[(�R�o�C�g�g�����߃R�[�h)
0005: 0D �@;..������2�o�C�g���Ԓn000D������
0006: 00 �@;..
0007: 80 �@;�`���W�X�^�̒l�Ƃa���W�X�^�̒l�����Z���Ă`���W�X�^�ɓ����
0008: 32 �@;000E�Ԓn�̃������ɂ`���W�X�^�̒l���R�s�[(�R�o�C�g�g�����߃R�[�h)
0009: 0E �@;..������2�o�C�g���Ԓn000E������
000A: 00 �@;..
000B: 76 �@;���߂����ԂɎ��s����̂��~�߂�
000C: 12 ;�f�[�^1
000D: 34 ;�f�[�^2
000E: 00 ;�f�[�^3 0000�Ԓn����v���O���������s����ƒl��46�ɕω�����
�@�B��Œ��ڃv���O���������̂͑�ςȂ̂ŁA�@�B��ɂP�P�Ή������A�Z���u���R�[�h�i�j�[���j�b�N�j�Ńv���O�������L�q���ϊ��\�ŋ@�B��ɖ|�� ���@���g����悤�ɂȂ�܂����B�ϊ���Ƃ̓v���O�����ōs���̂���ʓI�ŁA���̃v���O�������A�Z���u���iassembler�j�ƌ����܂��B�Ԓn�ɖ��O��t�������̂����x�����ƌ����Ԓn�̑���Ƀ��x�����Ńv���O�������L�q�ł���ȂǁA �@�B��Œ��ڃv���O�������L�q��������i�i�Ƀv���O���������₷���Ȃ�܂��B
�A�Z���u���R�[�h�̗�
| �A�Z���u���R�[�h | �Ӗ� | �@�B��ƃf�[�^ |
| LDA�@1234 | 1234�Ԓn����A���W�X�^�Ƀf�[�^���R�s�[ | 3A 34 12 |
| STA�@5678 | A���W�X�^����5678�Ԓn�Ƀf�[�^���R�s�[ | 32 78 56 |
| MOV B,A | A���W�X�^����B���W�X�^�Ƀf�[�^���R�s�[ | 47 |
| ADD B | ���W�X�^A��B�̒l�𑫂���A�Ɋi�[ | 80 |
| HLT | �v���O�����̎��s��~ | 76 |
| DC 01 23 | ���̌�Ɏ����l���������[�ɐݒ肷�� | 01 23 |
| DS�@2 | 2�o�C�g�������������� | ?? ?? |
�A�Z���u���v���O���� �Ԓn:�@�B��i16�i�\�L�j
PROG0 START 0000 ;�v���O����PROG0�̊J�n�ʒu�@0000�Ԓn
LDA XXXX 0000:3A 0C 00 ;XXXX�Ԓn�̒l��A���W�X�^�ɃR�s�[
MOV B,A 0003:47 ;A���W�X�^�̒l��B���W�X�^�ɃR�s�[
LDA YYYY 0004:3A 0D 00 ;YYYY�Ԓn�̒l��A���W�X�^�ɃR�s�[
ADD B 0007:80 ;A�{B����A
STA ZZZZ 0008:32 0E 00 ;A���W�X�^�̒l��ZZZZ�Ԓn�ɃR�s�[
HLT 000B:76 ;�v���O�����̎��s��~
XXXX DC 12 000C:12 ;�������[��16�i�Œl12���i�[
YYYY DC 34 000D:34 ;�������[��16�i�Œl34���i�[
ZZZZ DS 1 000E:00 ;1�o�C�g��������������
END ;�v���O����PROG0�̏I�[
���@�@�B��̔Ԓn��x���̒l�̓A�Z���u�����v�Z���Ă����
�A�Z���u���v���O�����͂ǂ̂悤�ȋ@�B��ɕϊ�����邩�����m�Ȕ��ʂŁA��͂蒷���v���O�������L�q����ɂ͂܂��܂��ɎG�����܂��B
����̗�ŃA�Z���u���R�[�h��1�s�ɑΉ�����@�B�ꂪ�����o�C�g�ɂȂ�Ƃ��́A1�s�ɕ����o�C�g����ׁA���̑�莟�̍s�̔Ԓn���o�C�g�������₵�Ă��܂��B���̂悤�ȔԒn�̌v�Z�̓A�Z���u���̃v���O����������Ă����̂ŁA�l�Ԃ͔Ԓn���v�Z�����Ƃ���������A�A�Z���u���Ńv���O���������Ƃ��̓��x����XXXX��YYYY�����Ԓn���l�Ԃ͌v�Z���Ȃ��čς݂܂��B
��蒊�ۓI�Ől�Ԃ��킩��Ղ��l�H��������A�|��v���O�����u�R���p�C ���v�ŋ@�B��ɖ|���@�ł��B�@�|��̂������̓R���p�C���ɔC���A�l�Ԃ͋@�B���v���O���������s����d�g�݂��ڂ����m��K�v������܂���B
�@�Ⴆ��C����ŁA�ȉ��̗l�ȍ��v�̌v�Z���܂ރv���O�������L�q���Aintel��x86�nCPU�̋@�B��ɖ|�Ă݂܂��B
#include <stdio.h>
int main( void ) {
char x,y,z;
/*�@16�i���̐��l��\���Ƃ��́@C����ł͓���0x��t���܂��@10�i��255��16�i�ł�0xFF�Ə����܂�*/
x=0x12;/*16�i����12��x�ɑ��*/
y=0x34;/*16�i����34��y�ɑ��*/
z=x+y; /*x+y�̒l��z�ɑ��*/
printf("%d",z);
return 0;
}
���v�̌v�Z�菇�͂ǂ̃��W�X�^���g�����A���������[�ɏ����o�����Ȃǖ����ɂ��邪�A�ǂ����邩�͖|��R���p�C���C���ł��B���������������[��ߖ邩�A���s���x�𑬂�����Ƃ������v�]���\ �Ȓ��x�ł��B
���ɖ|�ʂ������܂����Ax86�n�̋@�B���m��Ȃ��ƑS�R����܂���B �t�Ɍ�����x86�n�̋@�B���m��Ȃ��Ă��@�B��̃v���O��������ꂽ�킯�ŁA�v�Z�@���g�����߂Ƀv���O���������l�̕��S�͑傢�Ɍy������܂��B
�@�@�Ԓn:�@�B��@�@�@�@�@�@�@�@�Ή�����A�Z���u���R�[�h 00000000: 55 push ebp 00000001: 89 E5 mov ebp,esp 00000003: 83 EC 10 sub esp,16 00000006: C6 45 F4 12 mov byte ptr [ebp-12],18 �G������x=0x12�i16�i12��10�i��18�j 0000000A: C6 45 F8 34 mov byte ptr [ebp-8],52�@�G������y=0x34 (16�i34��10�i��52�j 0000000E: 8A 55 F4 mov dl,byte ptr [ebp-12] �Gdl���W�X�^��x���R�s�[ 00000011: 02 55 F8 add dl,byte ptr [ebp-8]�@�Gdl+y���v�Z��dl�ɑ�� 00000014: 88 55 FC mov byte ptr [ebp-4],dl�@�Gdl�̒l��z�ɃR�s�[ 00000017: 0F BE 45 FC movsx eax,byte ptr [ebp-4] ;���̌��printf�̌Ăяo������ 0000001B: 50 push eax 0000001C: 68 00 00 00 00 push offset _@2 00000021: E8 00 00 00 00 call _printf 00000026: 59 pop ecx 00000027: 59 pop ecx 00000028: B8 00 00 00 00 mov eax,0 ;���̌��return 0�̏��� 0000002D: C9 leave 0000002E: C3 ret near
�����F��L�̃v���O�����͖���v�Z���Ȃ��Ă����̒l�͌��܂��Ă��܂��B�����ŁA�œK�����s���R���p�C���ł���=0��46�Ɣ��f���A�����Z���Ȃ��@�@�B��v���O��������
�邩������܂���B�������x�A���̂��߂̃��������p�ӂ��܂���B���L�̗l�ȃv���O�����ɍœK�����Ă���@�B��ɕϊ����邩������Ȃ��̂ł��B
�@�R���p�C���͑����ĒZ���@�B��v���O�����ɂȂ�悤�ɍœK���̗͂������Ă��܂��B�R���p�C�����g���ƌv�Z�@�̎d�g�݂�����Ȃ��Ă��v���O���������܂��B�ł������̃v���O�����𒀌�����̂ɂȂ�Ƃ͌���܂���B
#include <stdio.h>
int main( void ) {
printf("%d",0x46);
return 0;
}
���ӁFC����̃v���O�������͊ԐړI�ł����@�B��̃v���O��������邱�Ƃł��B�A�Z���u������ő�K�͂ȃv���O�����������Ă����l�������A�����Ɖ���Ղ��v���O�������������߂ɍ�����̂�C����ł��i���ȏ�2P�j�B�v�Z�@�̎d�g�݂������͒m���Ă�����C����̕��@�̗������e�ՂɂȂ�܂��B�A�h���X�Ƃ����W�X�^�Ƃ��������t���o�Ă����Ƃ��A�������������Ă��������B
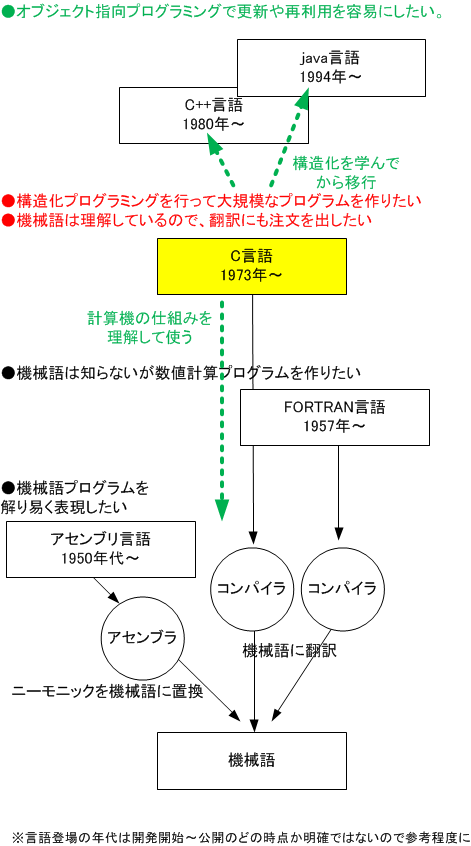
���v�Z�@�̎d�g�݂�m��Ȃ��Ă��v���O����������Čv�Z���ł���悤�ɂ��邽�߂�FORTRAN��COBOL�Ƃ������������ꂪ����܂����B���ہA����������g�����Ƃő����̐l���v�Z�@�𗘗p�ł���悤�ɂȂ�܂����B�������AC����͍����A�Z���u���ƌĂԐl��������ɁA�v�Z�@�̎d�g�݂�m������Ŏg������ł��B�g�ݍ��@��̐���v���O�������ɂ悭�g����̂͂��̂��߂ł��B
�v�Z�@�̋@�킲�Ƃɋ@�B��͐F�X�ł��B�A�Z���u���͋@�B����L�������A�Ή��\�ŋ@�B��ɕϊ����邾���ł��B�����v�Z���������Ă��A�A�Z���u���̃v���O�����ł͋@�킲�ƂɈႤ���̂������Ȃ���Ȃ�܂���B
����ŁA��������̃v���O�����i�Ⴆ��z=x+y�G�j�̏ꍇ�́A�ǂ̗l�ȋ@�B��ɖ|�邩�͌��ꏈ���n�ɔC����Ă��܂��B�����ŁA�v�Z�@�̋@��ɂ��Ⴂ�����ꏈ���n�ŋz�����A���ꂼ��̋@��ɉ������@�B��֖|�邱�Ƃ��ł��܂��B
�����ꏈ���n
�|��v���O�����ȂǁA���̃v���O������������s���邽�߂ɗp�ӂ��ꂽ�v���O�����̎��s���B
������������̃v���O������|�ŐF�X�ȋ@��̋@�B��֖|���ł��B�v�Z�@�̋@�킲�Ƃɖ|���̃v���O������p�ӂł���A������������̃v���O�O�������F�X�Ȍv�Z�@�œ����悤�Ɏ��s�ł��܂��B
�v���O���~���O���ꗘ�p�Ґ������L���O�̍ŏ�ʂ�java��C��C++�ł��B���̉Ȗڂł͍\��������ł���C������w�сA��K�͂ȃv���O����������ł̊�b�����܂��BC�̓I�u�W�F�N�g�w�������java��C++���w�ԏ�ł̊�b�ɂ��Ȃ�܂��B�����ɁAC�͌v�Z�@�̎d�g�݂𗝉����ď��Ɏg�����Ƃ��\�ɂ��Ă���܂��B
��java�͌v�Z�@�̃n�[�h�E�G�A������Ă������悤�ɓ������Ƃ��d����������ŁA�n�[�h�E�G�A�̋@�\���ő���Ɏg���悤�ȏ����͏����܂���B����ɑ��āAC�͌v�Z�@�̃n�[�h�E�G�A���ő���ɗ��p�ł��錾��Ƃ��č��ꂽ�Ƃ�������������܂��B���̂��Ƃ�java��C/C++�̐��ݕ����Ɍq�����Ă��܂��B
��1980�N���C�ɃI�u�W�F�N�g�w���v���O�����������₷������@�\��lj����č��ꂽ�̂�C++����ł��BC++���ꏈ���n�̑�����C++�����łȂ�C�̃R���p�C�����p�ӂ��Ă��܂��B���̂悤��C++��C�R���p�C���̑�����C����̋K�iC89�i1989�N�j�Ή��ƂȂ��Ă��܂��B�������A�V�����K�iC99�i1999�N�j��C11�i2011�N�j�ɂ͕����I�ɂ����Ή����Ă��Ȃ��̂�����ł��B
�葱���^ �v���O���~���O�iProcedural programming�j�ł̓f�[�^����������葱�����g���ăf�[�^�����Ԃɉ��H���Č��ʂ܂��B�@�B�ꃌ�x���ł���@�B��̖��߂����ԂɎ��s���邱�ƂŖړI�̌��ʂ܂��BC����̏ꍇ�͎�����̗l�Ȃ܂Ƃ܂����葱�����g�����ƂŁA�v���O���~���O�͂������I�ɂȂ�܂��B�@�������A�����������߂Ƀv���O��������鑤�ŋ�̓I�ȉ�@�菇���l���A������v���O�����Ƃ��ċL�q���邱�Ƃ��K�v�Ȃ͓̂����ł��B
C����̃v���O�������@�B��ւƖ|��̂̓v���O������1���߂��Ƃɋ@�B��ɖ|�����̂����Ԃɕ��ׂ�����̂ŊȒP�ł��B�������A
���ۂ͍œK���ƌĂ��������I�ȋ@�B��ɖ|��@�\�����߂�ꌾ�ꏈ���n�i�R���p�C���Ȃǁj�͕��G�����Ă��܂��B
�����ꏈ���n�ilanguage processor�j�F�v���O���~���O����ŏ����ꂽ�v���O�������@�B��ɂ܂Ƃ߂Ė|��icompile�j�A���邢�͂��̂܂ܒ���
���ߎ��s�iinterpret�j����d�g�݁B
��葱���^�̌���Ƃ́@�����������߂̋�̓I�ȉ��Z�菇���v���O�����ŋL�q����̂ł͂Ȃ��A�O�������v�����v���O�����Ƃ��ċL�q �����ꏈ���n�ɗv�������菇����C����^�C�v�̌���ł��B
�@�B��͌v�Z�@�̐��䖽�߂��L�q������̂Ȃ̂Ŏ葱�I�ł��B��葱�^�v���O��������������ɂ͗v������������ �菇�����o���K�v���� ��A�����ɍl������菇����œK�ɋ߂����̂�I�����邱�Ƃ��K�v�ł��B���ꏈ���n�̕��S�͑傫�����A�v���O�������������͋�̓I�菇���l����K�v���������������S������A�v���O���~���O���e�ՂɂȂ�ƌ����Ă��܂��B�ȉ��̂悤�ȗႪ�L��B
- LISP�F
- Prolog�F�@http://bach.scitec.kobe-u.ac.jp/prolog/
- SQL�F�����[�V���i���f�[�^�x�[�X�̐v�A����i�X�V�A�����j�Ɏg����W���I�Ȍ���B